五、使用卷积神经网络实现深度计算机视觉
译者:@SeanCheney
尽管 IBM 的深蓝超级计算机在 1996 年击败了国际象棋世界冠军加里·卡斯帕罗夫,但直到最近计算机才能从图片中认出小狗,或是识别出说话时的单词。为什么这些任务对人类反而毫不费力呢?原因在于,感知过程不属于人的自我意识,而是属于专业的视觉、听觉和其它大脑感官模块。当感官信息抵达意识时,信息已经具有高级特征了:例如,当你看一张小狗的图片时,不能选择不可能,也不能回避的小狗的可爱。你解释不了你是如何识别出来的:小狗就是在图片中。因此,我们不能相信主观经验:感知并不简单,要明白其中的原理,必须探究感官模块。
卷积神经网络(CNN)起源于人们对大脑视神经的研究,自从 1980 年代,CNN 就被用于图像识别了。最近几年,得益于算力提高、训练数据大增,以及第 11 章中介绍过的训练深度网络的技巧,CNN 在一些非常复杂的视觉任务上取得了超出人类表现的进步。CNN 支撑了图片搜索、无人驾驶汽车、自动视频分类,等等。另外,CNN 也不再限于视觉,比如:语音识别和自然语言处理,但这一章只介绍视觉应用。
本章会介绍 CNN 的起源,CNN 的基本组件以及 TensorFlow 和 Keras 实现方法。然后会讨论一些优秀的 CNN 架构,和一些其它的视觉任务,比如目标识别(分类图片中的多个物体,然后画框)、语义分割(按照目标,对每个像素做分类)。
视神经结构
David H. Hubel 和 Torsten Wiesel 在 1958 年和 1959 年在猫的身上做了一系列研究,对视神经中枢做了研究(并在 1981 年荣获了诺贝尔生理学或医学奖)。特别的,他们指出视神经中的许多神经元都有一个局部感受野(local receptive field),也就是说,这些神经元只对有限视觉区域的刺激作反应(见图 14-1,五个神经元的局部感受野由虚线表示)。不同神经元的感受野或许是重合的,拼在一起就形成了完整的视觉区域。
另外,David H. Hubel 和 Torsten Wiesel 指出,有些神经元只对横线有反应,而其它神经元可能对其它方向的线有反应(两个神经元可能有同样的感受野,但是只能对不同防线的线有反应)。他们还注意到,一些神经元有更大的感受野,可以处理更复杂的图案,复杂图案是由低级图案构成的。这些发现启发人们,高级神经元是基于周边附近低级神经元的输出(图 14-1 中,每个神经元只是连着前一层的几个神经元)。这样的架构可以监测出视觉区域中各种复杂的图案。
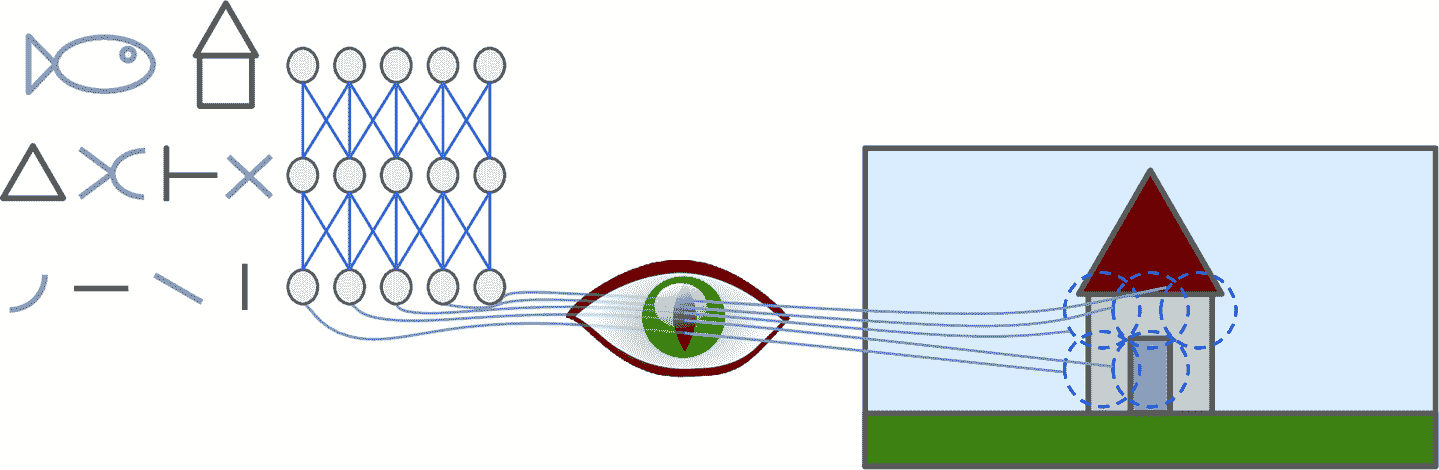
图 14-1 视神经中生物神经元可以对感受野中的图案作反应;当视神经信号上升时,神经元可以反应出更大感受野中的更为复杂的图案
对视神经的研究在 1980 年启发了神经认知学,后者逐渐演变成了今天的卷积神经网络。Yann LeCun 等人再 1998 年发表了一篇里程碑式的论文,提出了著名的 LeNet-5 架构,被银行广泛用来识别手写支票的数字。这个架构中的一些组件,我们已经学过了,比如全连接层、sigmod 激活函数,但 CNN 还引入了两个新组件:卷积层和池化层。
笔记:为什么不使用全连接层的深度神经网络来做图像识别呢?这是因为,尽管这种方案在小图片(比如 MNIST)任务上表现不错,但由于参数过多,在大图片任务上表现不佳。举个例子,一张`100 × 100·像素的图片总共有 10000 个像素点,如果第一层有 1000 个神经元(如此少的神经元,已经限制信息的传输量了),那么就会有 1000 万个连接。这仅仅是第一层的情况。CNN 是通过部分连接层和权重共享解决这个问题的。
卷积层
卷积层是 CNN 最重要的组成部分:第一个卷积层的神经元,不是与图片中的每个像素点都连接,而是只连着局部感受野的像素(见图 14-2)。同理,第二个卷积层中的每个神经元也只是连着第一层中一个小方形内的神经元。这种架构可以让第一个隐藏层聚焦于小的低级特征,然后在下一层组成大而高级的特征,等等。这种层级式的结构在真实世界的图片很常见,这是 CNN 能在图片识别上取得如此成功的原因之一。
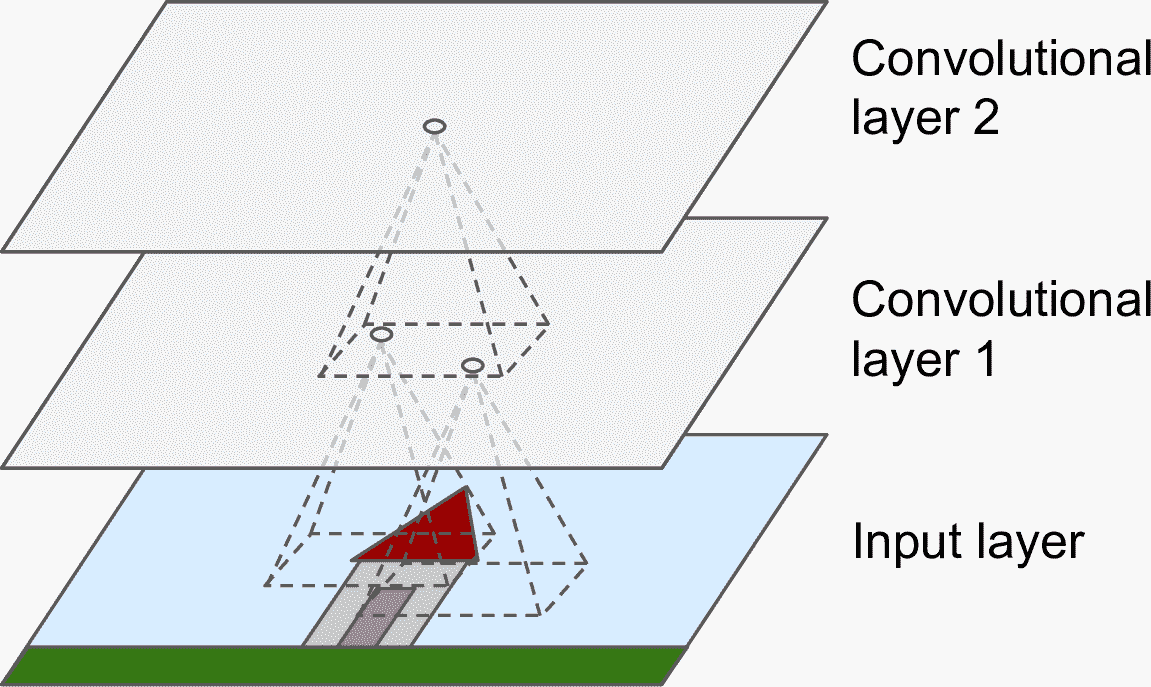
图 14-2 有方形局部感受野的 CNN 层
笔记:我们目前所学过的所有多层神经网络的层,都是由一长串神经元组成的,所以在将图片输入给神经网络之前,必须将图片打平成 1D 的。在 CNN 中,每个层都是 2D 的,更容易将神经元和输入做匹配。
位于给定层第i行、第j列的神经元,和前一层的第i行到第i + fh – 1行、第j列到第j + fw – 1列的输出相连,f[h]和f[w]是感受野的高度和宽度(见图 14-3)。为了让卷积层能和前一层有相同的高度和宽度,通常给输入加上 0,见图,这被称为零填充(zero padding)。
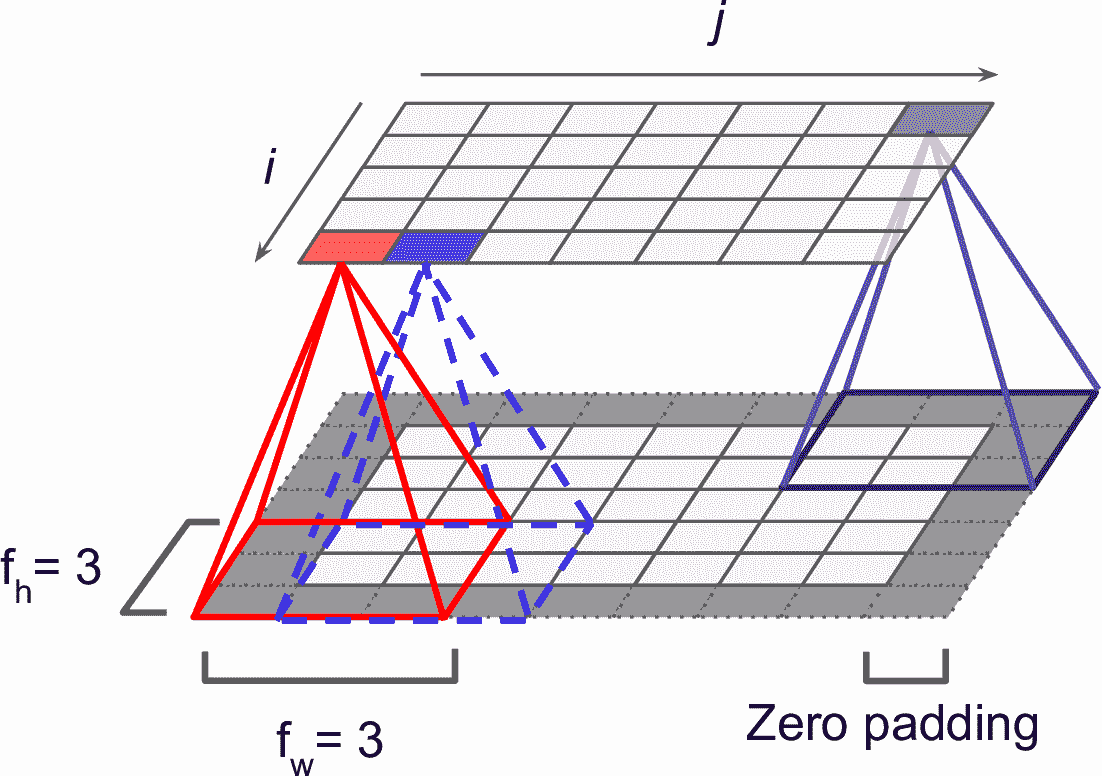
图 14-3 卷积层和零填充的连接
也可以通过间隔感受野,将大输入层和小卷积层连接起来,见图 14-4。这么做可以极大降低模型的计算复杂度。一个感受野到下一个感受野的便宜距离称为步长。在图中,5 × 7的输入层(加上零填充),连接着一个3 × 4的层,使用3 × 3的感受野,步长是 2(这个例子中,宽和高的步长都是 2,但也可以不同)。位于上层第i行、第j列的神经元,连接着前一层的第i × sh到i × sh + fh – 1行、第j × sw到j × sw + fw – 1列的神经元的输出,s[h]和s[w]分别是垂直和水平步长。
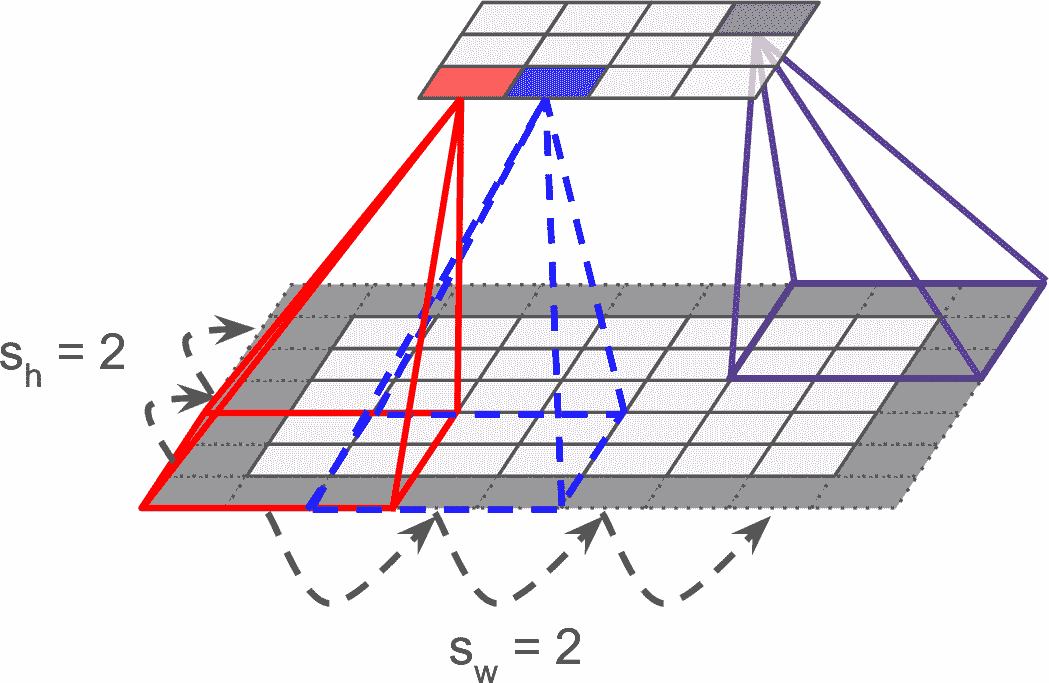
图 14-2 使用大小为 2 的步长降维
过滤器
神经元的权重可以表示为感受野大小的图片。例如,图 14-5 展示了两套可能的权重(称为权重,或卷积核)。第一个是黑色的方形,中央有垂直白线(7 × 7的矩阵,除了中间的竖线都是 1,其它地方是 0);使用这个矩阵,神经元只能注意到中间的垂直线(因为其它地方都乘以 0 了)。第二个过滤器也是黑色的方形,但是中间是水平的白线。使用这个权重的神经元只会注意中间的白色水平线。
如果卷积层的所有神经元使用同样的垂直过滤器(和同样的偏置项),给神经网络输入图 14-5 中最底下的图片,卷积层输出的是左上的图片。可以看到,图中垂直的白线得到了加强,其余部分变模糊了。相似的,右上的图是所有神经元都是用水平线过滤器的结果,水平的白线加强了,其余模糊了。因此,一层的全部神经元都用一个过滤器,就能输出一个特征映射(feature map),特征映射可以高亮图片中最为激活过滤器的区域。当然,不用手动定义过滤器:卷积层在训练中可以自动学习对任务最有用的过滤器,上面的层则可以将简单图案组合为复杂图案。
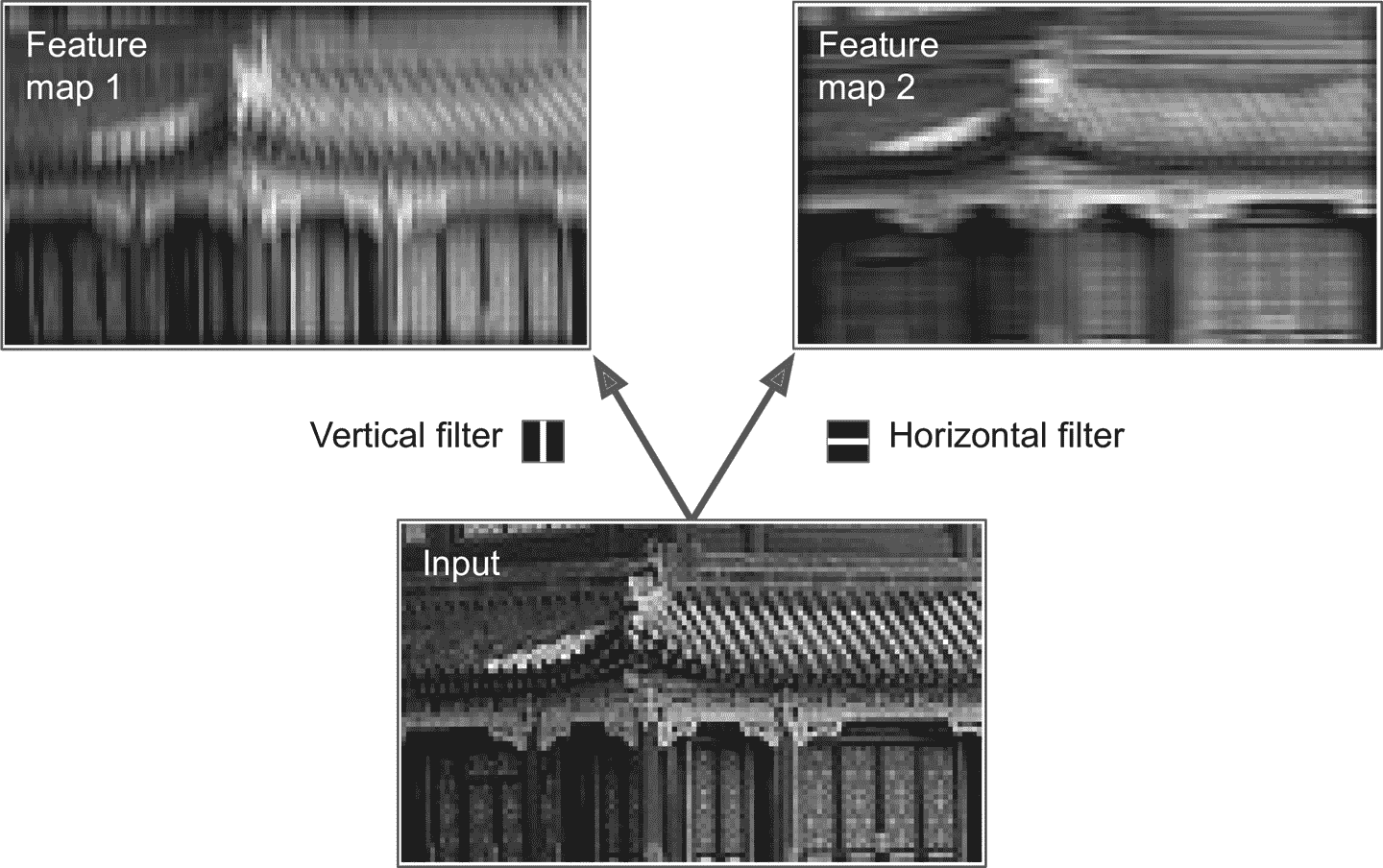
图 14-5 应用两个不同的过滤器,得到两张不同的特征映射
堆叠多个特征映射
简单起见,前面都是将每个卷积层的输出用 2D 层来表示的,但真实的卷积层可能有多个过滤器(过滤器数量由你确定),每个过滤器会输出一个特征映射,所以表示成 3D 更准确(见图 14-6)。每个特征映射的每个像素有一个神经元,同一特征映射中的所有神经元有同样的参数(即,同样的权重和偏置项)。不同特征映射的神经元的参数不同。神经元的感受野和之前描述的相同,但扩展到了前面所有的特征映射。总而言之,一个卷积层同时对输入数据应用多个可训练过滤器,使其可以检测出输入的任何地方的多个特征。
笔记:同一特征映射中的所有神经元共享一套参数,极大地减少了模型的参数量。当 CNN 认识了一个位置的图案,就可以在任何其它位置识别出来。相反的,当常规 DNN 学会一个图案,只能在特定位置识别出来。
输入图像也是有多个子层构成的:每个颜色通道,一个子层。通常是三个:红,绿,蓝(RGB)。灰度图只有一个通道,但有些图可能有多个通道 —— 例如,卫星图片可以捕捉到更多的光谱频率(比如红外线)。
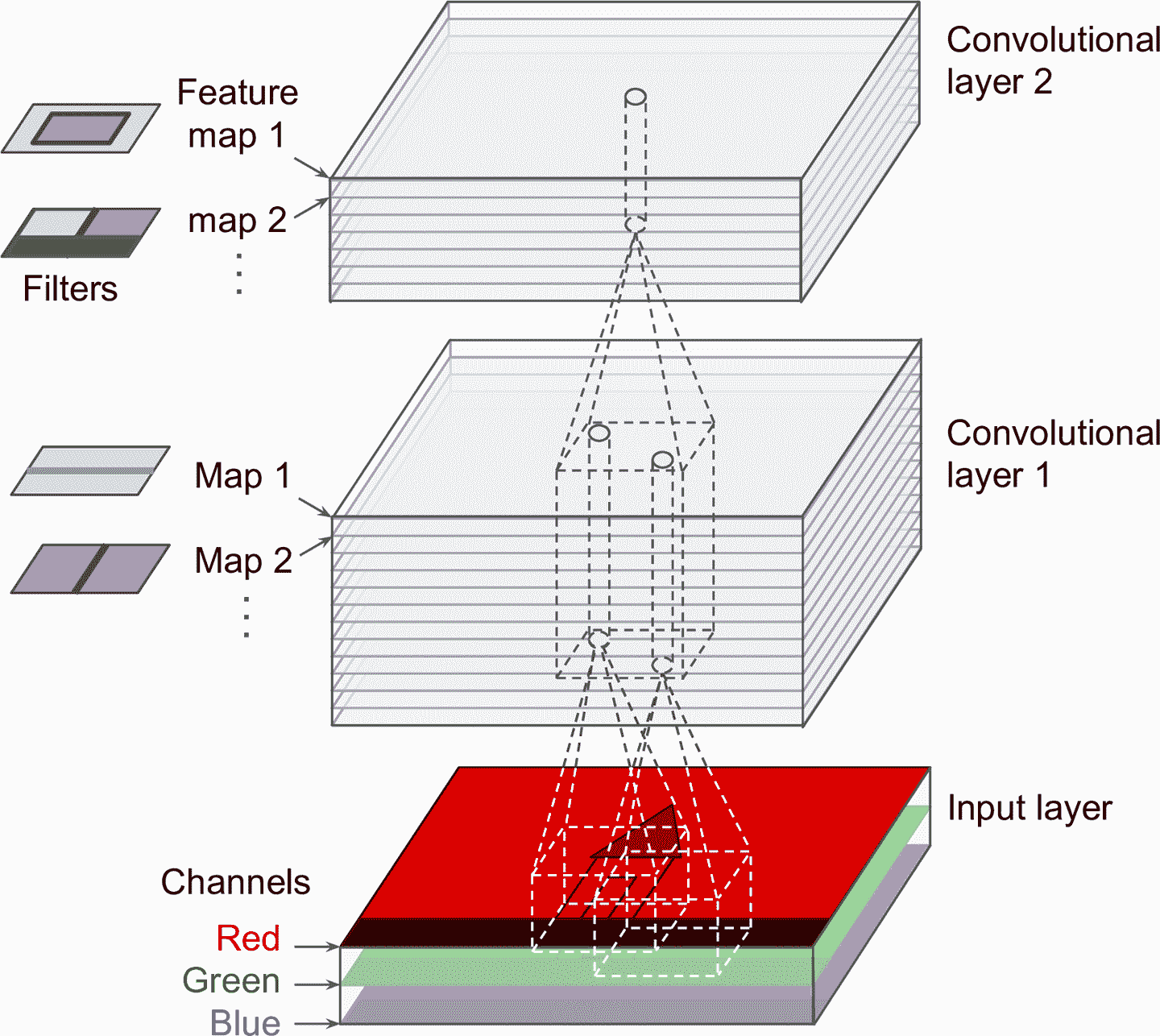
图 14-6 有多个特征映射的卷积层,有三个颜色通道的图像
特别的,位于卷积层l的特征映射k的第i行、第j列的神经元,它连接的是前一层l-1的i × sh到i × sh + fh – 1行、j × sw到j × sw + fw – 1列的所有特征映射。不同特征映射中,位于相同i行、j列的神经元,连接着前一层相同的神经元。
等式 14-1 用一个大等式总结了前面的知识:如何计算卷积层中给定神经元的输出。因为索引过多,这个等式不太好看,它所做的其实就是计算所有输入的加权和,再加上偏置项。
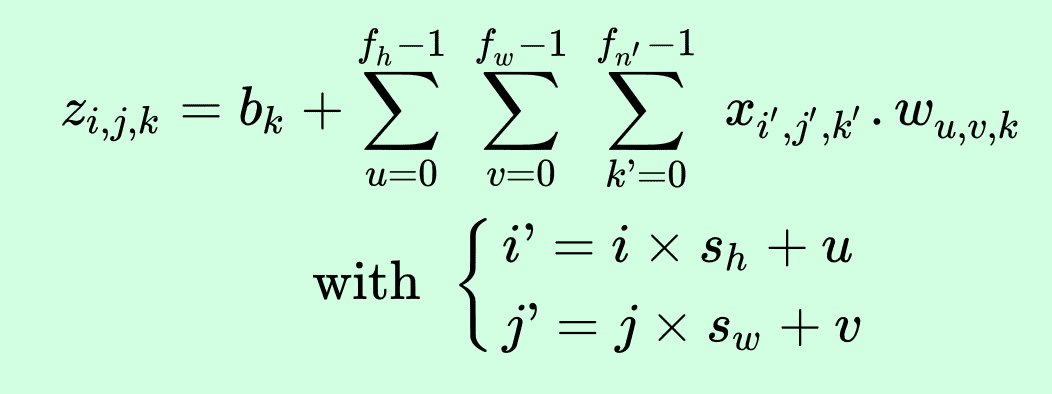
公式 14-1 计算卷积层中给定神经元的输出
在这个等式中:
-
z[i, j, k]是卷积层l中第i行、第j列、特征映射k的输出。 -
s[h]和s[w]是垂直和水平步长,f[h]和f[w]是感受野的高和宽,f[n']是前一层l-1的特征映射数。 -
x[i', j', k']是卷积层l-1中第i'行、第j'列、特征映射k'的输出(如果前一层是输入层,则为通道k')。 -
b[k]是特征映射k的偏置项。可以将其想象成一个旋钮,可以调节特征映射 k 的明亮度。 -
w[u, v, k′ ,k]是层l的特征映射k的任意神经元,和位于行u、列v(相对于神经元的感受野)、特征映射k'的输入,两者之间的连接权重。
TensorFlow 实现
在 TensorFlow 中,每张输入图片通常都是用形状为[高度,宽度,通道]的 3D 张量表示的。一个小批次则为 4D 张量,形状是[批次大小,高度,宽度,通道]。卷积层的权重是 4D 张量,形状是[f[h], f[w], f[n'], f[n]]。卷积层的偏置项是 1D 张量,形状是[f[n]]。
看一个简单的例子。下面的代码使用 Scikit-Learn 的load_sample_image()加载了两张图片,一张是中国的寺庙,另一张是花,创建了两个过滤器,应用到了两张图片上,最后展示了一张特征映射:
from sklearn.datasets import load_sample_image
# 加载样本图片
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# 创建两个过滤器
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 垂直线
filters[3, :, :, 1] = 1 # 水平线
outputs = tf.nn.conv2d(images, filters, strides=1, padding="same")
plt.imshow(outputs[0, :, :, 1], cmap="gray") # 画出第 1 张图的第 2 个特征映射
plt.show()
逐行看下代码:
-
每个颜色通道的像素强度是用 0 到 255 来表示的,所以直接除以 255,将其缩放到区间 0 到 1 内。
-
然后创建了两个
7 × 7的过滤器(一个有垂直正中白线,另一个有水平正中白线)。 -
使用
tf.nn.conv2d()函数,将过滤器应用到两张图片上。这个例子中使用了零填充(padding="same"),步长是 1。 -
最后,画出一个特征映射(相似与图 14-5 中的右上图)。
tf.nn.conv2d()函数这一行,再多说说:
-
images是一个输入的小批次(4D 张量)。 -
filters是过滤器的集合(也是 4D 张量)。 -
strides等于 1,也可以是包含 4 个元素的 1D 数组,中间的两个元素是垂直和水平步长(s[h]和s[w]),第一个和最后一个元素现在必须是 1。以后可以用来指定批次步长(跳过实例)和通道步长(跳过前一层的特征映射或通道)。 -
padding必须是"same"或"valid": -
如果设为
"same",卷积层会使用零填充。输出的大小是输入神经元的数量除以步长,再取整。例如:如果输入大小是 13,步长是 5(见图 14-7),则输出大小是 3(13 / 5 = 2.6,再向上圆整为 3),零填充尽量在输入上平均添加。当strides=1时,层的输出会和输入有相同的空间维度(宽和高),这就是same的来历。 -
如果设为
"valid",卷积层就不使用零填充,取决于步长,可能会忽略图片的输入图片的底部或右侧的行和列,见图 14-7(简单举例,只是显示了水平维度)。这意味着每个神经元的感受野位于严格确定的图片中的位置(不会越界),这就是valid的来历。
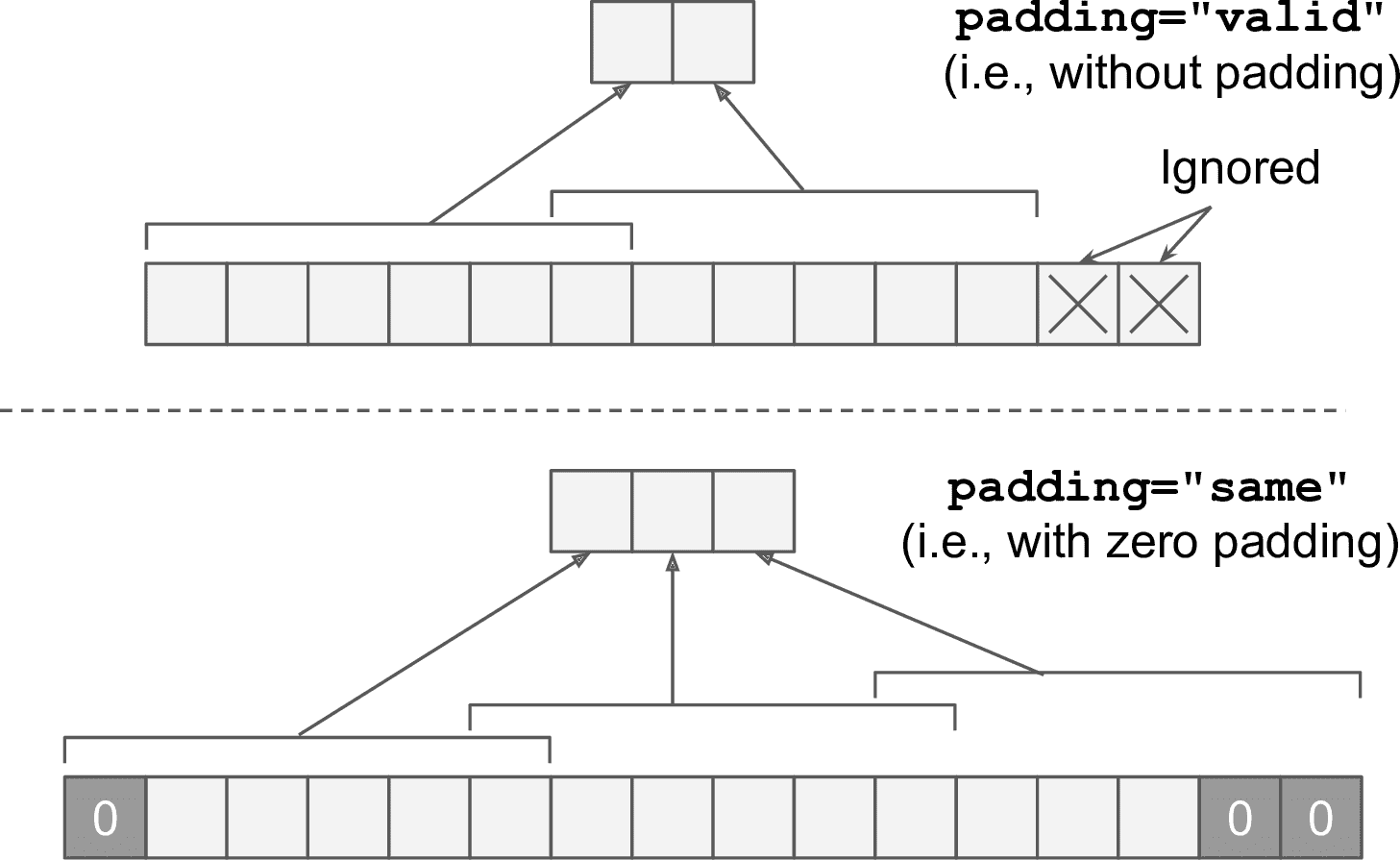
图 14-7 Padding="same"或"valid"(输入宽度 13,过滤器宽度 6,步长 5)
这个例子中,我们手动定义了过滤器,但在真正的 CNN 中,一般将过滤器定义为可以训练的变量,好让神经网络学习哪个过滤器的效果最好。使用keras.layers.Conv2D层:
conv = keras.layers.Conv2D(filters=32, kernel_size=3, strides=1,
padding="same", activation="relu")
这段代码创建了一个有 32 个过滤器的Conv2D层,每个过滤器的形状是3 × 3,步长为 1(水平垂直都是 1),和"same"填充,输出使用 ReLU 激活函数。可以看到,卷积层的超参数不多:选择过滤器的数量,过滤器的高和宽,步长和填充类型。和以前一样,可以使用交叉验证来找到合适的超参数值,但很耗时间。后面会讨论常见的 CNN 架构,可以告诉你如何挑选超参数的值。
内存需求
CNN 的另一个问题是卷积层需要很高的内存。特别是在训练时,因为反向传播需要所有前向传播的中间值。
比如,一个有5 × 5个过滤器的卷积层,输出 200 个特征映射,大小为150 × 100,步长为 1,零填充。如果如数是150 × 100的 RGB 图片(三通道),则参数总数是(5 × 5 × 3 + 1) × 200 = 15200,加 1 是考虑偏置项。相对于全连接层,参数少很多了。但是 200 个特征映射,每个都包含150 × 100个神经元,每个神经元都需要计算5 × 5 × 3 = 75个输入的权重和:总共是 2.25 亿个浮点数乘法运算。虽然比全连接层少点,但也很耗费算力。另外,如果特征映射用的是 32 位浮点数,则卷积层输出要占用200 × 150 × 100 × 32 = 96百万比特(12MB)的内存。这仅仅是一个实例,如果训练批次有 100 个实例,则要使用 1.2 GB 的内存。
在做推断时(即,对新实例做预测),下一层计算完,前一层占用的内存就可以释放掉内存,所以只需要两个连续层的内存就够了。但在训练时,前向传播期间的所有结果都要保存下来以为反向传播使用,所以消耗的内存是所有层的内存占用总和。
提示:如果因为内存不够发生训练终端,可以降低批次大小。另外,可以使用步长降低纬度,或去掉几层。或者,你可以使用 16 位浮点数,而不是 32 位浮点数。或者,可以将 CNN 分布在多台设备上。
接下来,看看 CNN 的第二个组成部分:池化层。
池化层
明白卷积层的原理了,池化层就容易多了。池化层的目的是对输入图片做降采样(即,收缩),以降低计算负载、内存消耗和参数的数量(降低过拟合)。
和卷积层一样,池化层中的每个神经元也是之和前一层的感受野里的有限个神经元相连。和前面一样,必须定义感受野的大小、步长和填充类型。但是,池化神经元没有权重,它所要做的是使用聚合函数,比如最大或平均,对输入做聚合。图 14-8 展示了最为常用的最大池化层。在这个例子中,使用了一个2 × 2的池化核,步长为 2,没有填充。只有感受野中的最大值才能进入下一层,其它的就丢弃了。例如,在图 14-8 左下角的感受野中,输入值是 1、5、3、2,所以只有最大值 5 进入了下一层。因为步长是 2,输出图的高度和宽度是输入图的一半(因为没有用填充,向下圆整)。
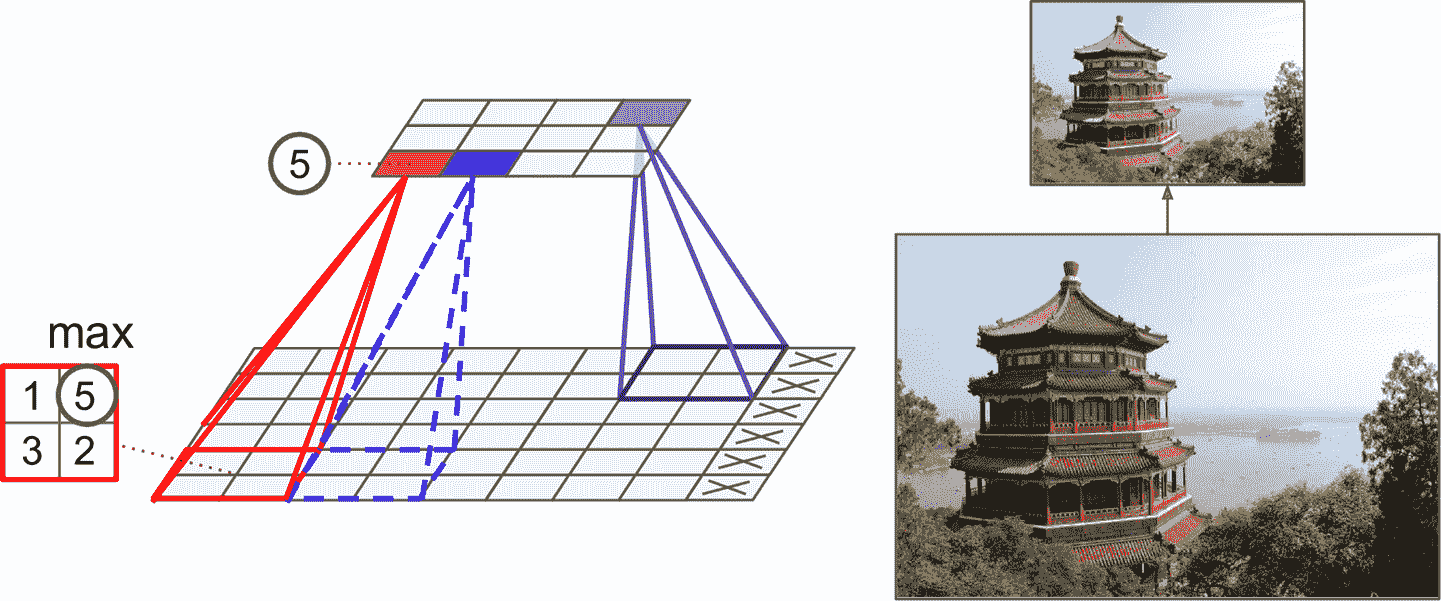
图 14-8 最大池化层(2 × 2的池化核,步长为 2,没有填充)
笔记:池化层通常独立工作在每个通道上,所以输出深度和输入深度相同。
除了可以减少计算、内存消耗、参数数量,最大池化层还可以带来对小偏移的不变性,见图 14-9。假设亮像素比暗像素的值小,用2 × 2核、步长为 2 的最大池化层处理三张图(A、B、C)。图 B 和 C 的图案与 A 相同,只是分别向右移动了一个和两个像素。可以看到,A、B 经过池化层处理后的结果相同,这就是所谓的平移不变性。对于图片 C,输出有所不同:向右偏移了一个像素(但仍然有 50% 没变)。在 CNN 中每隔几层就插入一个最大池化层,可以带来更大程度的平移不变性。另外,最大池化层还能带来一定程度的旋转不变性和缩放不变性。当预测不需要考虑平移、旋转和缩放时,比如分类任务,不变性可以有一定益处。
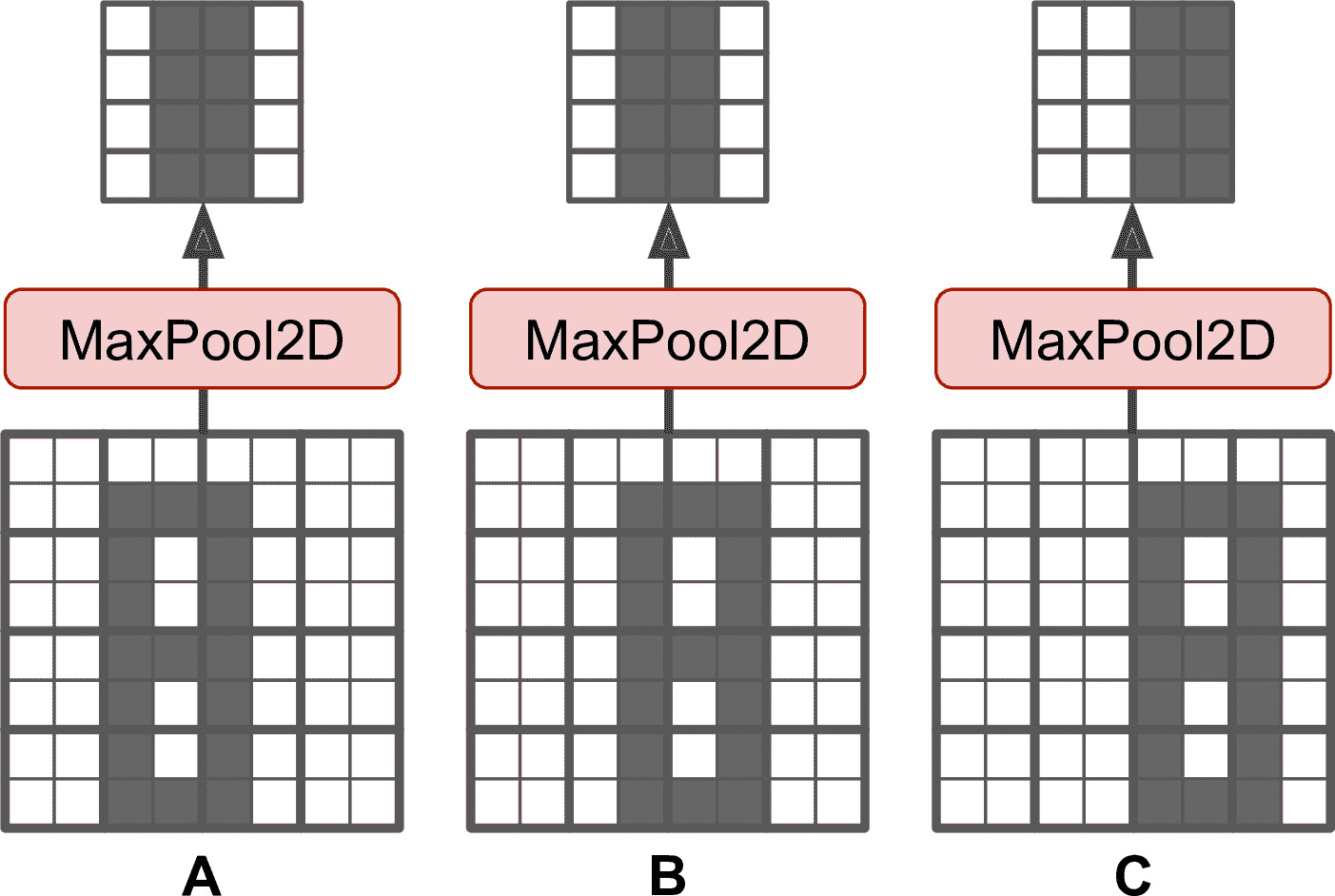
图 14-9 小平移不变性
但是,最大池化层也有缺点。首先,池化层破坏了信息:即使感受野的核是2 × 2,步长是 2,输出在两个方向上都损失了一半,总共损失了 75% 的信息。对于某些任务,不变性不可取。比如语义分割(将像素按照对象分类):如果输入图片向右平移了一个像素,输出也应该向右平移一个降速。此时强调的就是等价:输入发生小变化,则输出也要有对应的小变化。
TensorFlow 实现
用 TensorFlow 实现最大池化层很简单。下面的代码实现了最大池化层,核是2 × 2。步长默认等于核的大小,所以步长是 2(水平和垂直步长都是 2)。默认使用"valid"填充:
max_pool = keras.layers.MaxPool2D(pool_size=2)
要创建平均池化层,则使用AvgPool2D。平均池化层和最大池化层很相似,但计算的是感受野的平均值。平均池化层在过去很流行,但最近人们使用最大池化层更多,因为最大池化层的效果更好。初看很奇怪,因为计算平均值比最大值损失的信息要少。但是从反面看,最大值保留了最强特征,去除了无意义的特征,可以让下一层获得更清楚的信息。另外,最大池化层提供了更强的平移不变性,所需计算也更少。
池化层还可以沿着深度方向做计算。这可以让 CNN 学习到不同特征的不变性。比如。CNN 可以学习多个过滤器,每个过滤器检测一个相同的图案的不同旋转(比如手写字,见图 14-10),深度池化层可以使输出相同。CNN 还能学习其它的不变性:厚度、明亮度、扭曲、颜色,等等。
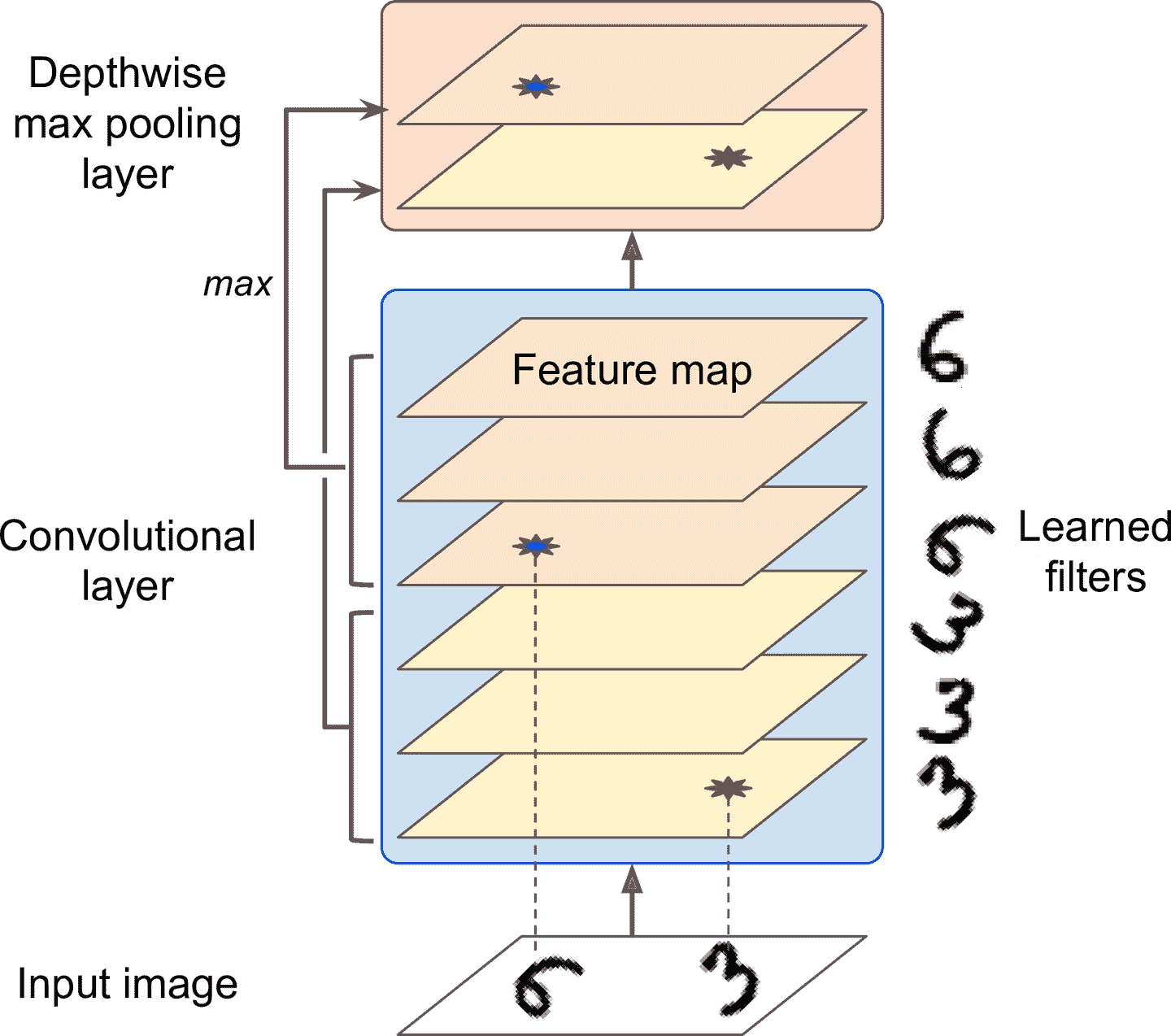
图 14-10 深度最大池化层可以让 CNN 学习到多种不变性
Keras 没有深度方向最大池化层,但 TensorFlow 的低级 API 有:使用tf.nn.max_pool(),指定核的大小、步长(4 元素的元组):元组的前三个值应该是 1,表明沿批次、高度、宽度的步长是 1;最后一个值,是深度方向的步长 —— 比如 3(深度步长必须可以整除输入深度;如果前一个层有 20 个特征映射,步长 3 就不成):
output = tf.nn.max_pool(images,
ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3),
padding="valid")
如果想将这个层添加到 Keras 模型中,可以将其包装进Lambda层(或创建一个自定义 Keras 层):
depth_pool = keras.layers.Lambda(
lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3), strides=(1, 1, 1, 3),
padding="valid"))
最后一中常见的池化层是全局平均池化层。它的原理非常不同:它计算整个特征映射的平均值(就像是平均池化层的核的大小和输入的空间维度一样)。这意味着,全局平均池化层对于每个实例的每个特征映射,只输出一个值。虽然这么做对信息的破坏性很大,却可以用来做输出层,后面会看到例子。创建全局平均池化层的方法如下:
global_avg_pool = keras.layers.GlobalAvgPool2D()
它等同于下面的Lambda层:
global_avg_pool = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))
介绍完 CNN 的组件之后,来看看如何将它们组合起来。
CNN 架构
CNN 的典型架构是将几个卷积层叠起来(每个卷积层后面跟着一个 ReLU 层),然后再叠一个池化层,然后再叠几个卷积层(+ReLU),接着再一个池化层,以此类推。图片在流经神经网络的过程中,变得越来越小,但得益于卷积层,却变得越来越深(特征映射变多了),见图 14-11。在 CNN 的顶部,还有一个常规的前馈神经网络,由几个全连接层(+ReLU)组成,最终层输出预测(比如,一个输出类型概率的 softmax 层)。
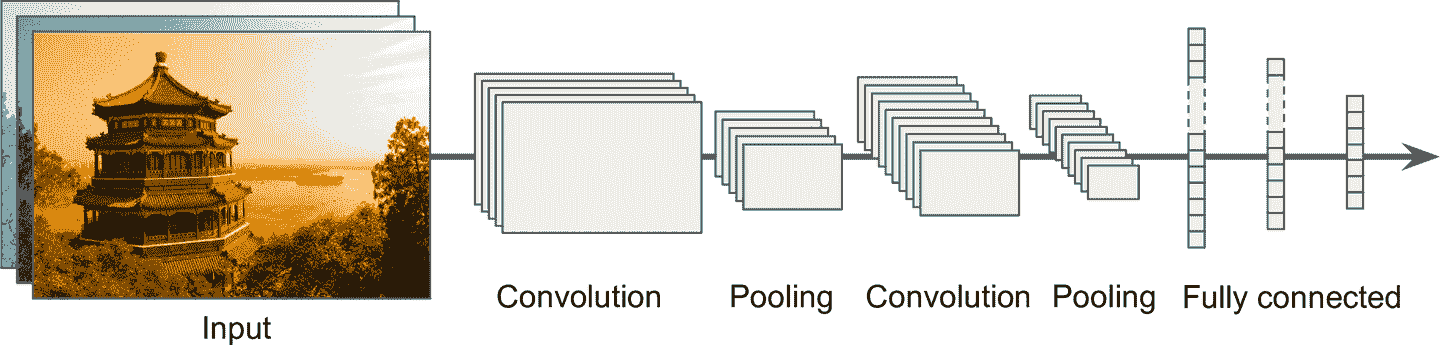
图 14-11 典型的 CNN 架构
提示:常犯的错误之一,是使用过大的卷积核。例如,要使用一个卷积层的核是
5 × 5,再加上两个核为3 × 3的层:这样参数不多,计算也不多,通常效果也更好。第一个卷积层是例外:可以有更大的卷积核(例如5 × 5),步长为 2 或更大:这样可以降低图片的空间维度,也没有损失很多信息。
下面的例子用一个简单的 CNN 来处理 Fashion MNIST 数据集(第 10 章介绍过):
model = keras.models.Sequential([
keras.layers.Conv2D(64, 7, activation="relu", padding="same",
input_shape=[28, 28, 1]),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="softmax")
])
逐行看下代码:
-
第一层使用了 64 个相当大的过滤器(
7 × 7),但没有用步长,因为输入图片不大。还设置了input_shape=[28, 28, 1],因为图片是28 × 28像素的,且是单通道(即,灰度)。 -
接着,使用了一个最大池化层,核大小为 2.
-
接着,重复做两次同样的结构:两个卷积层,跟着一个最大池化层。对于大图片,这个结构可以重复更多次(重复次数是超参数)。
-
要注意,随着 CNN 向着输出层的靠近,过滤器的数量一直在提高(一开始是 64,然后是 128,然后是 256):这是因为低级特征的数量通常不多(比如,小圆圈或水平线),但将其组合成为高级特征的方式很多。通常的做法是在每个池化层之后,将过滤器的数量翻倍:因为池化层对空间维度除以了 2,因此可以将特征映射的数量翻倍,且不用担心参数数量、内存消耗、算力的增长。
-
然后是全连接网络,由两个隐藏紧密层和一个紧密输出层组成。要注意,必须要打平输入,因为紧密层的每个实例必须是 1D 数组。还加入了两个丢弃层,丢弃率为 50%,以降低过拟合。
这个 CNN 可以在测试集上达到 92% 的准确率。虽然不是顶尖水平,但也相当好了,效果比第 10 章用的方法好得多。
过去几年,这个基础架构的变体发展迅猛,取得了惊人的进步。衡量进步的一个指标是 ILSVRC ImageNet challenge 的误差率。在六年期间,这项赛事的前五误差率从 26% 降低到了 2.3%。前五误差率的意思是,预测结果的前 5 个最高概率的图片不包含正确结果的比例。测试图片相当大(256 个像素),有 1000 个类,一些图的差别很细微(比如区分 120 种狗的品种)。学习 ImageNet 冠军代码是学习 CNN 的好方法。
我们先看看经典的 LeNet-5 架构(1998),然后看看三个 ILSVRC 竞赛的冠军:AlexNet(2012)、GoogLeNet(2014)、ResNet(2015)。
LeNet-5
LeNet-5 也许是最广为人知的 CNN 架构。前面提到过,它是由 Yann LeCun 在 1998 年创造出来的,被广泛用于手写字识别(MNIST)。它的结构如下:
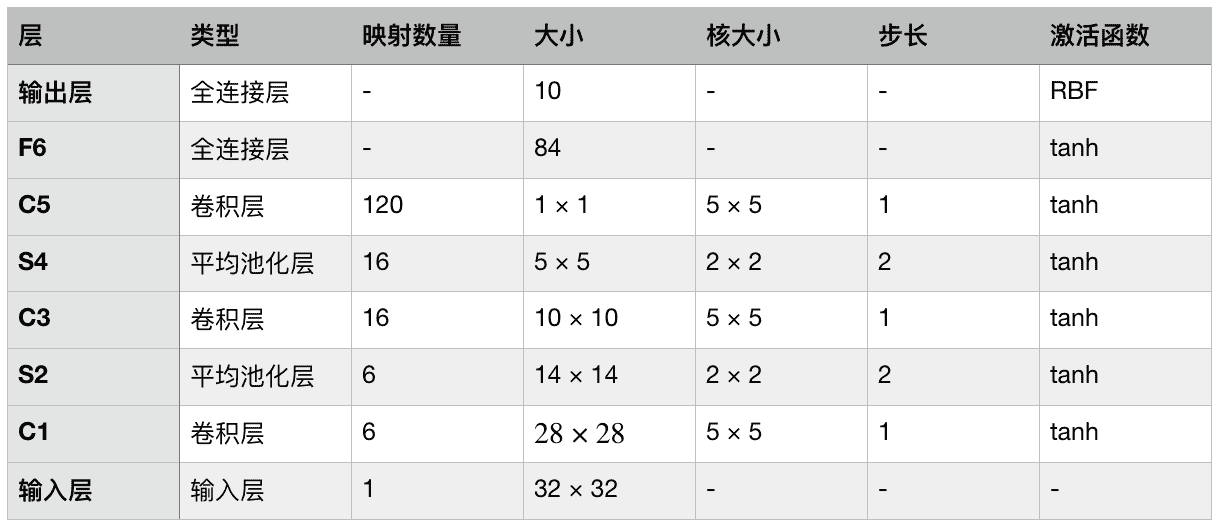
表 14-1 LeNet-5 架构
有一些点需要注意:
-
MNIST 图片是
28 × 28像素的,但在输入给神经网络之前,做了零填充,成为32 × 32像素,并做了归一化。后面的层不用使用任何填充,这就是为什么当图片在网络中传播时,图片大小持续缩小。 -
平均池化层比一般的稍微复杂点:每个神经元计算输入的平均值,然后将记过乘以一个可学习的系数(每个映射一个系数),在加上一个可学习的偏置项(也是每个映射一个),最后使用激活函数。
-
C3 层映射中的大部分神经元,只与 S2 层映射三个或四个神经元全连接(而不是 6 个)。
-
输出层有点特殊:不是计算输入和权重向量的矩阵积,而是每个神经元输出输入向量和权重向量的欧氏距离的平方。每个输出衡量图片属于每个数字类的概率程度。这里适用交叉熵损失函数,因为对错误预测惩罚更多,可以产生更大的梯度,收敛更快。
Yann LeCun 的网站展示了 LeNet-5 做数字分类的例子。
AlexNet
AlexNet CNN 架构以极大优势,赢得了 2012 ImageNet ILSVRC 冠军:它的 Top-5 误差率达到了 17%,第二名只有 26%!它是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 发明的。AlexNet 和 LeNet-5 很相似,只是更大更深,是首个将卷积层堆叠起来的网络,而不是在每个卷积层上再加一个池化层。表 14-2 展示了其架构:
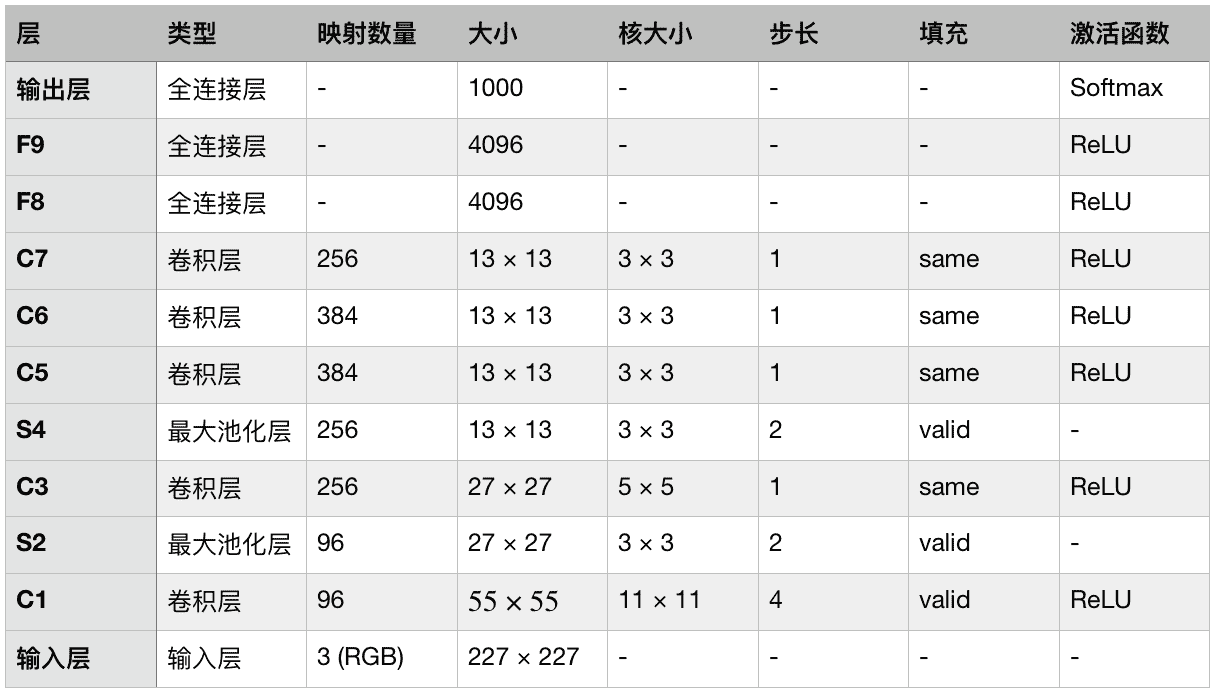
表 14-2 AlexNet 架构
为了降低过拟合,作者使用了两种正则方法。首先,F8 和 F9 层使用了丢弃,丢弃率为 50%。其次,他们通过随机距离偏移训练图片、水平翻转、改变亮度,做了数据增强。
数据增强
数据增强是通过生成许多训练实例的真实变种,来人为增大训练集。因为可以降低过拟合,成为了一种正则化方法。生成出来的实例越真实越好:最理想的情况,人们无法区分增强图片是原生的还是增强过的。简单的添加白噪声没有用,增强修改要是可以学习的(白噪声不可学习)。
例如,可以轻微偏移、旋转、缩放原生图,再添加到训练集中(见图 14-12)。这么做可以使模型对位置、方向和物体在图中的大小,有更高的容忍度。如果想让模型对不同光度有容忍度,可以生成对比度不同的照片。通常,还可以水平翻转图片(文字不成、不对称物体也不成)。通过这些变换,可以极大的增大训练集。
图 14-12 从原生图生成新的训练实例

AlexNet 还在 C1 和 C3 层的 ReLU 之后,使用了强大的归一化方法,称为局部响应归一化(LRN):激活最强的神经元抑制了相同位置的相邻特征映射的神经元(这样的竞争性激活也在生物神经元上观察到了)。这么做可以让不同的特征映射专业化,特征范围更广,提升泛化能力。等式 14-2 展示了如何使用 LRN。
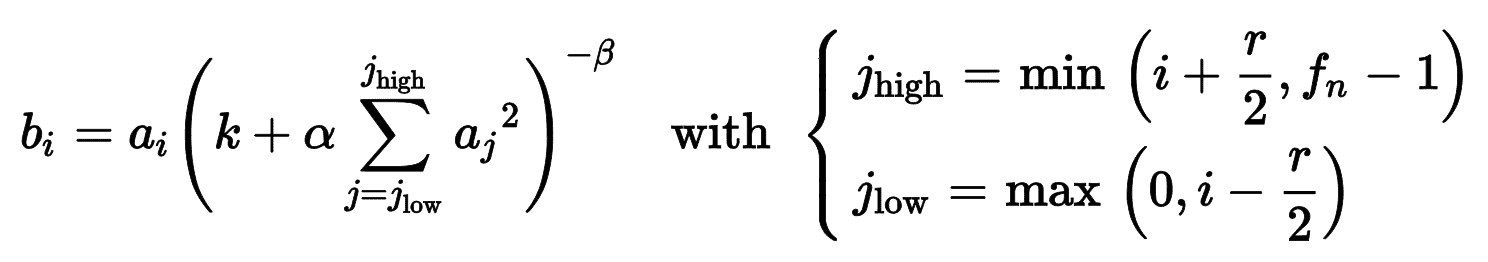
公式 14-2 局部响应归一化(LRN)
这这个等式中:
-
b[I]是特征映射i的行u列v的神经元的归一化输出(注意等始中没有出现行u列v)。 -
a[I]是 ReLu 之后,归一化之前的激活函数。 -
k、α、β和r是超参。k是偏置项,r是深度半径。 -
f[n]是特征映射的数量。
例如,如果r=2,且神经元有强激活,能抑制其他相邻上下特征映射的神经元的激活。
在 AlexNet 中,超参数是这么设置的:r = 2,α = 0.00002,β = 0.75,k = 1。可以通过tf.nn.local_response_normalization()函数实现,要想用在 Keras 模型中,可以包装进Lambda层。
AlexNet 的一个变体是 ZF Net,是由 Matthew Zeiler 和 Rob Fergus 发明的,赢得了 2013 年的 ILSVRC。它本质上是对 AlexNet 做了一些超参数的调节(特征映射数、核大小,步长,等等)。
GoogLeNet
GoogLeNet 架构是 Google Research 的 Christian Szegedy 及其同事发明的,赢得了 ILSVRC 2014 冠军,top-5 误差率降低到了 7% 以内。能取得这么大的进步,很大的原因是它的网络比之前的 CNN 更深(见图 14-14)。这归功于被称为创始模块(inception module)的子网络,它可以让 GoogLeNet 可以用更高的效率使用参数:实际上,GoogLeNet 的参数量比 AlexNet 小 10 倍(大约是 600 万,而不是 AlexNet 的 6000 万)。
图 14-13 展示了一个创始模块的架构。3 × 3 + 1(S)的意思是层使用的核是3 × 3,步长是 1,"same"填充。先复制输入信号,然后输入给 4 个不同的层。所有卷积层使用 ReLU 激活函数。注意,第二套卷积层使用了不同的核大小(1 × 1、3 × 3、5 × 5),可以让其捕捉不同程度的图案。还有,每个单一层的步长都是 1,都是零填充(最大池化层也同样),因此它们的输出和输入有同样的高度和宽度。这可以让所有输出在最终深度连接层,可以沿着深度方向连起来(即,将四套卷积层的所有特征映射堆叠起来)。这个连接层可以使用用tf.concat()实现,其axis=3(深度方向的轴)。
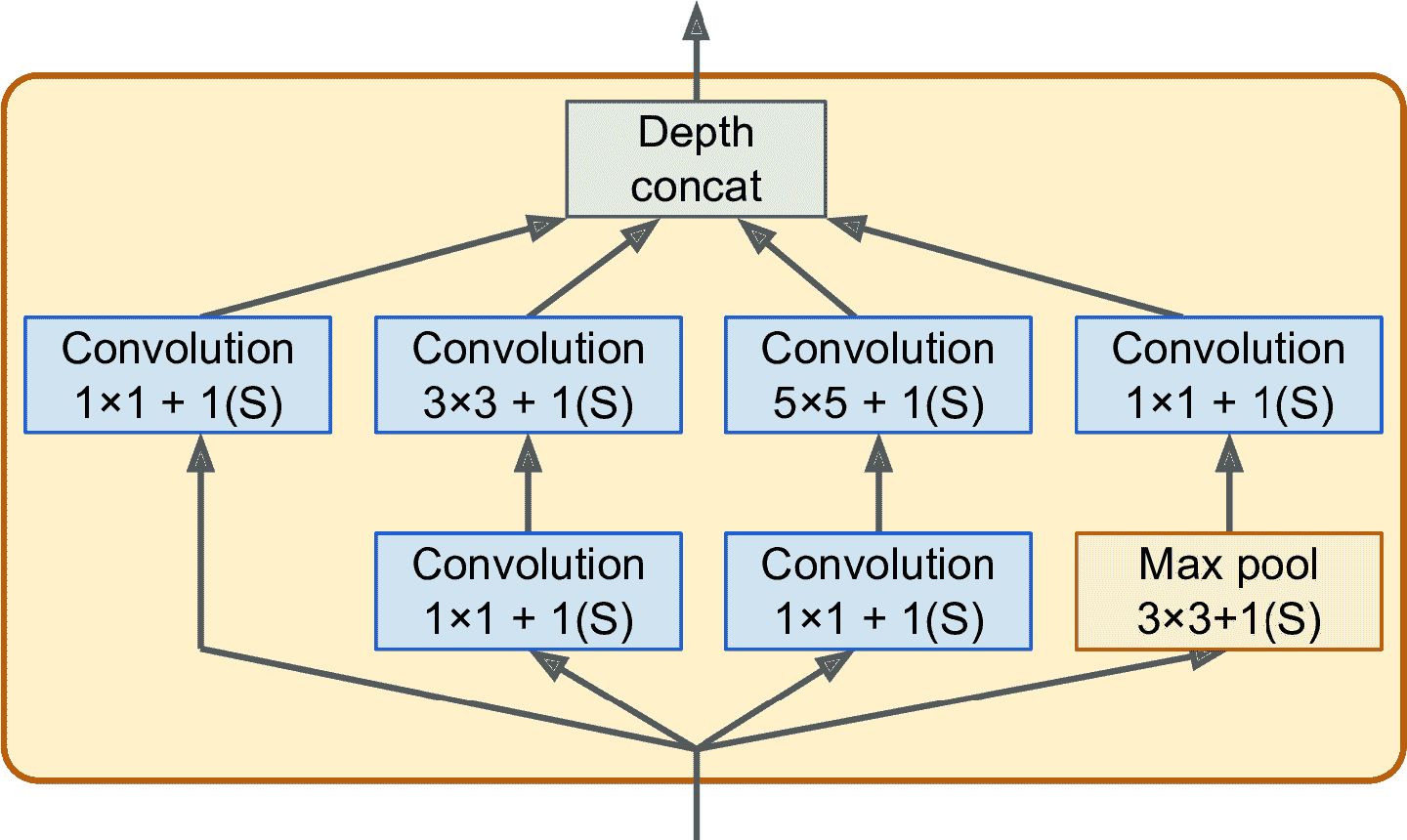
图 14-13 创始模块
为什么创始模块有核为1 × 1的卷积层呢?这些层捕捉不到任何图案,因为只能观察一个像素?事实上,这些层有三个目的:
-
尽管不能捕捉空间图案,但可以捕捉沿深度方向的图案。
-
这些曾输出的特征映射比输入少,是作为瓶颈层来使用的,意味它们可以降低维度。这样可以减少计算和参数量、加快训练,提高泛化能力。
-
每一对卷积层([1 × 1, 3 × 3] 和 [1 × 1, 5 × 5])就像一个强大的单一卷积层,可以捕捉到更复杂的图案。事实上,这对卷积层可以扫过两层神经网络。
总而言之,可以将整个创始模块当做一个卷积层,可以输出捕捉到不同程度、更多复杂图案的特征映射。
警告:每个卷积层的卷积核的数量是一个超参数。但是,这意味着每添加一个创始层,就多了 6 个超参数。
来看下 GoogLeNet 的架构(见图 14-14)。每个卷积层、每个池化层输出的特征映射的数量,展示在核大小的前面。因为比较深,只好摆成三列。GoogLeNet 实际是一列,一共包括九个创始模块(带有陀螺标志)。创始模块中的六个数表示模块中的每个卷积层输出的特征映射数(和图 14-13 的顺序相同)。注意所有卷积层使用 ReLU 激活函数。
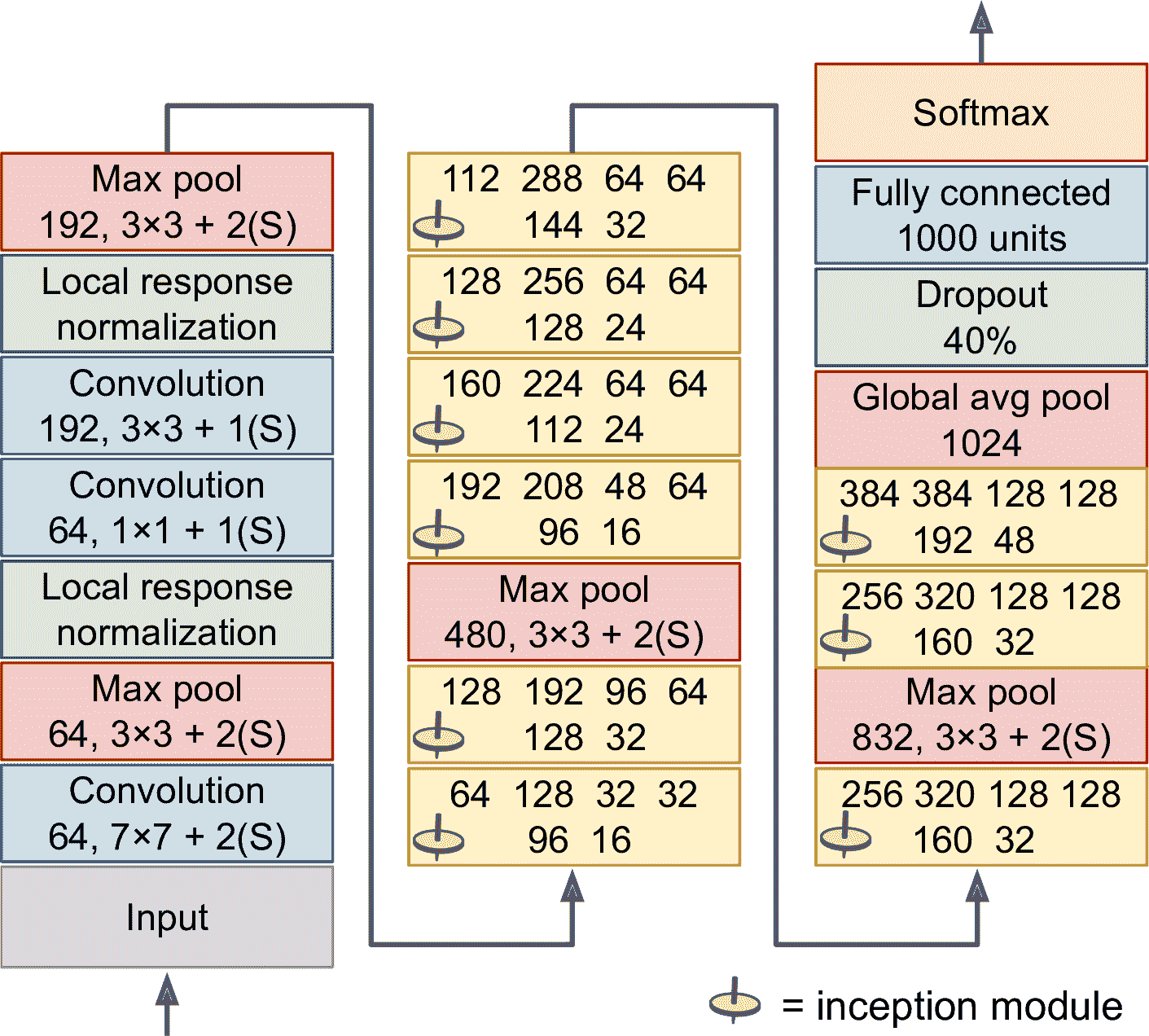
图 14-14 GoogLeNet 的架构
这个网络的结构如下:
-
前两个层将图片的高和宽除以了 4(所以面积除以了 16),以减少计算。第一层使用的核很大,可以保留大部分信息。
-
接下来,局部响应归一化层可以保证前面的层可以学到许多特征。
-
后面跟着两个卷积层,前面一层作为瓶颈层。可以将这两层作为一个卷积层。
-
然后,又是一个局部响应归一化层。
-
接着,最大池化层将图片的高度和宽度除以 2,以加快计算。
-
然后,是九个创始模块,中间插入了两个最大池化层,用来降维提速。
-
接着,全局平均池化层输出每个特征映射的平均值:可以丢弃任何留下的空间信息,可以这么做是因为此时留下的空间信息也不多了。事实上 GoogLeNet 的输入图片一般是
224 × 224像素的,经过 5 个最大池化层后,每个池化层将高和宽除以 2,特征映射降为7 × 7。另外,这是一个分类任务,不是定位任务,所以对象在哪无所谓。得益于该层降低了维度,就不用的网络的顶部(像 AlexNet 那样)加几个全连接层了,这么做可以极大减少参数数量,降低过拟合。 -
最后几层很明白:丢弃层用来正则,全连接层(因为有 1000 个类,所以有 1000 个单元)和 softmax 激活函数用来产生估计类的概率。
架构图经过轻微的简化:原始 GoogLeNet 架构还包括两个辅助的分类器,位于第三和第六创始模块的上方。它们都是由一个平均池化层、一个卷积层、两个全连接层和一个 softmax 激活层组成。在训练中,它们的损失(缩减 70%)被添加到总损失中。它们的目标是对抗梯度消失,对网络做正则。但是,后来的研究显示它们的作用很小。
Google 的研究者后来又提出了几个 GoogLeNet 的变体,包括 Inception-v3 和 Inception-v4,使用的创始模块略微不同,性能更好。
VGGNet
ILSVRC 2014 年的亚军是 VGGNet,作者是来自牛津大学 Visual Geometry Group(VGC)的 Karen Simonyan 和 Andrew Zisserman。VGGNet 的架构简单而经典,2 或 3 个卷积层和 1 个池化层,然后又是 2 或 3 个卷积层和 1 个池化层,以此类推(总共达到 16 或 19 个卷积层)。最终加上一个有两个隐藏层和输出层的紧密网络。VGGNet 只用3 × 3的过滤器,但数量很多。
ResNet
何凯明使用残差网络(或 ResNet)赢得了 ILSVRC 2015 的冠军,top-5 误差率降低到了 3.6% 以下。ResNet 的使用了极深的卷积网络,共 152 层(其它的变体有 1450 或 152 层)。反映了一个总体趋势:模型变得越来越深,参数越来越少。训练这样的深度网络的方法是使用跳连接(也被称为快捷连接):输入信号添加到更高层的输出上。
当训练神经网络时,目标是使网络可以对目标函数h(x)建模。如果将输入x添加给网络的输出(即,添加一个跳连接),则网络就要对f(x) = h(x) – x建模,而不是h(x)。这被称为残差学习(见图 14-15)。
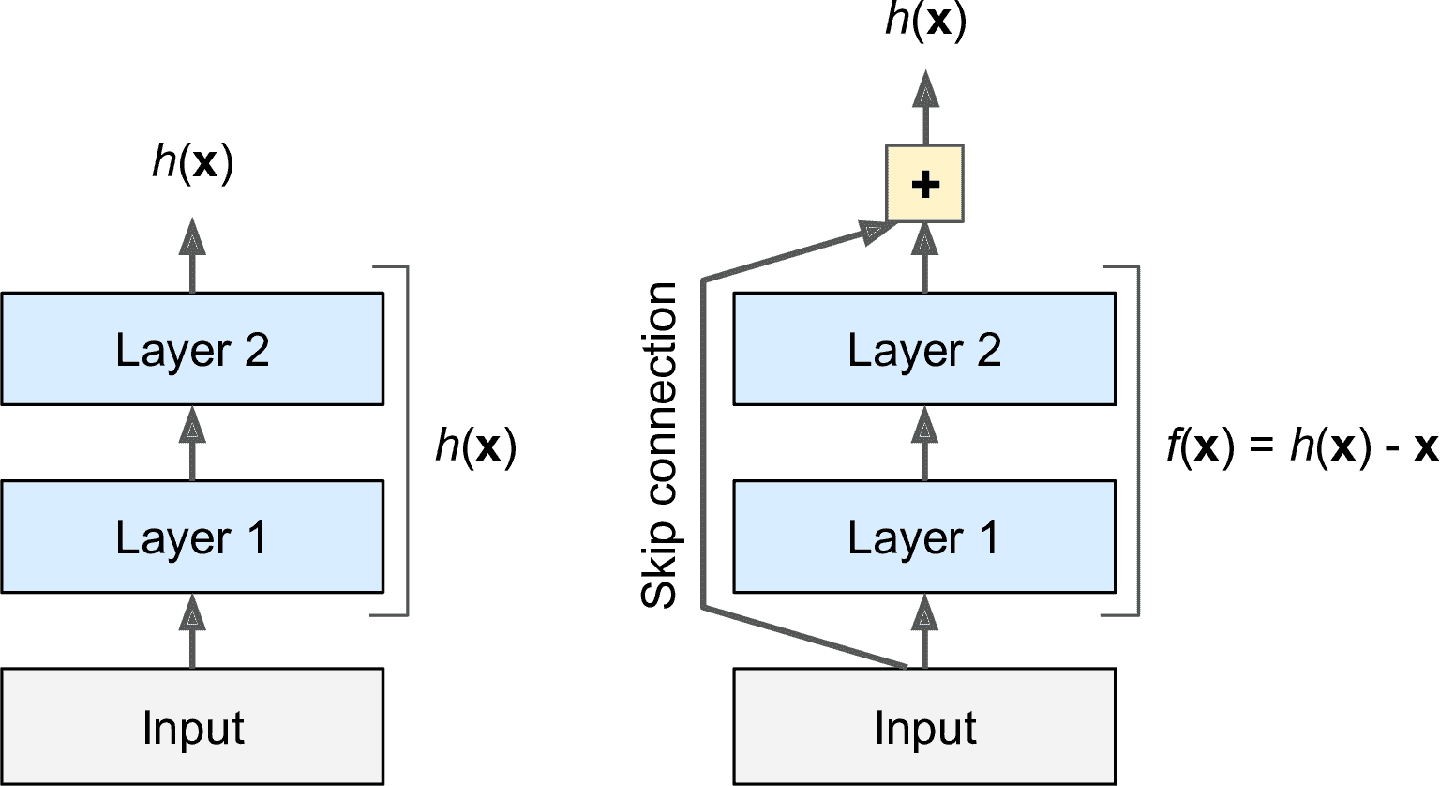
图 14-15 残差学习
初始化一个常规神经网络时,它的权重接近于零,所以输出值也接近于零。如果添加跳连接,网络就会输出一个输入的复制;换句话说,网络一开始是对恒等函数建模。如果目标函数与恒等函数很接近(通常会如此),就能极大的加快训练。
另外,如果添加多个跳连接,就算有的层还没学习,网络也能正常运作(见图 14-16)。多亏了跳连接,信号可以在整个网络中流动。深度残差网络,可以被当做残差单元(RU)的堆叠,其中每个残差单元是一个有跳连接的小神经网络。
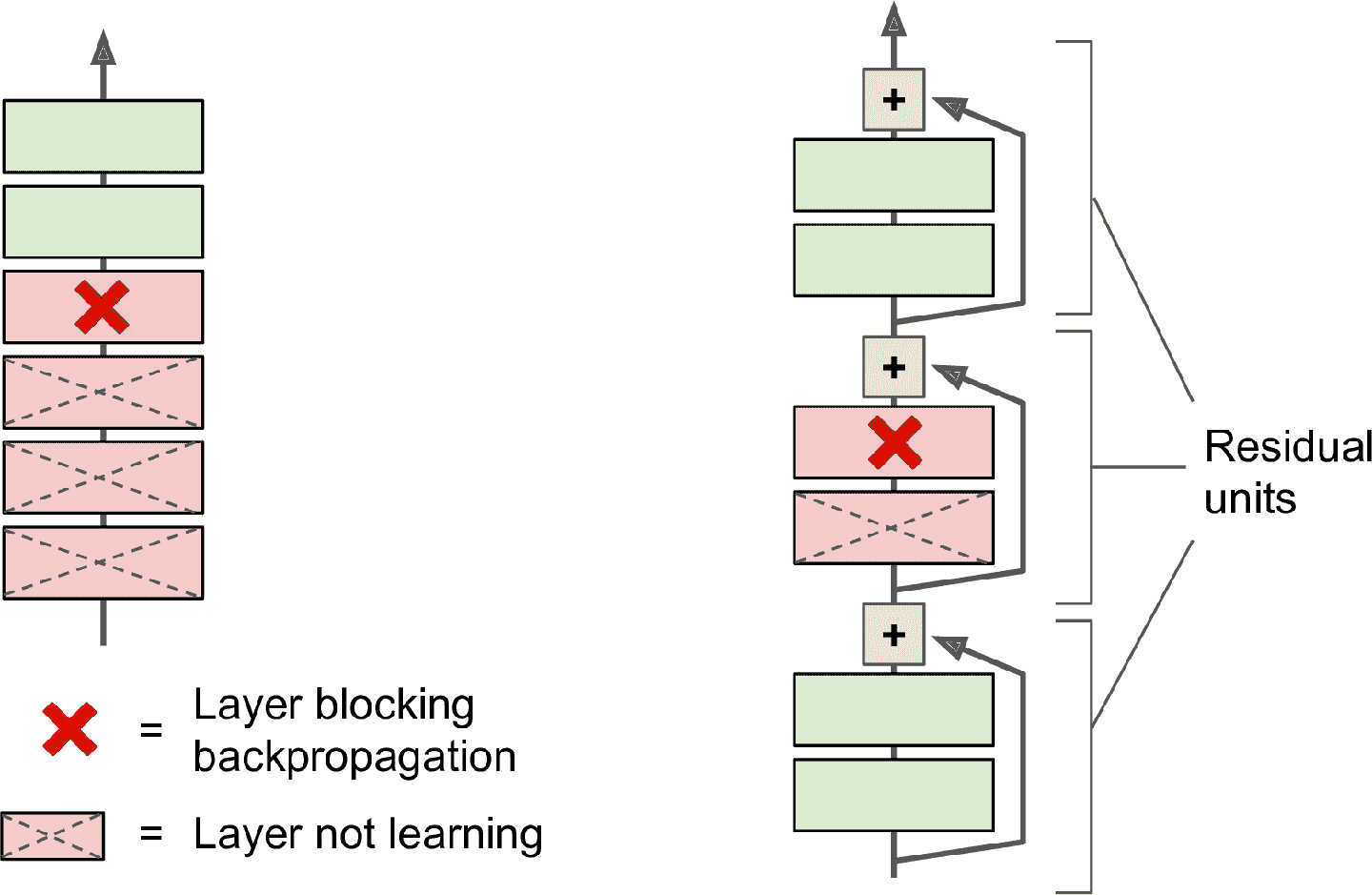
图 14-16 常规神经网络(左)和深度残差网络(右)
来看看 ResNet 的架构(见图 14-17)。特别简单。开头和结尾都很像 GoogLeNet(只是没有丢弃层),中间是非常深的残差单元的堆砌。每个残差单元由两个卷积层(没有池化层!)组成,有批归一化和 ReLU 激活,使用3 × 3的核,保留空间维度(步长等于 1,零填充)。
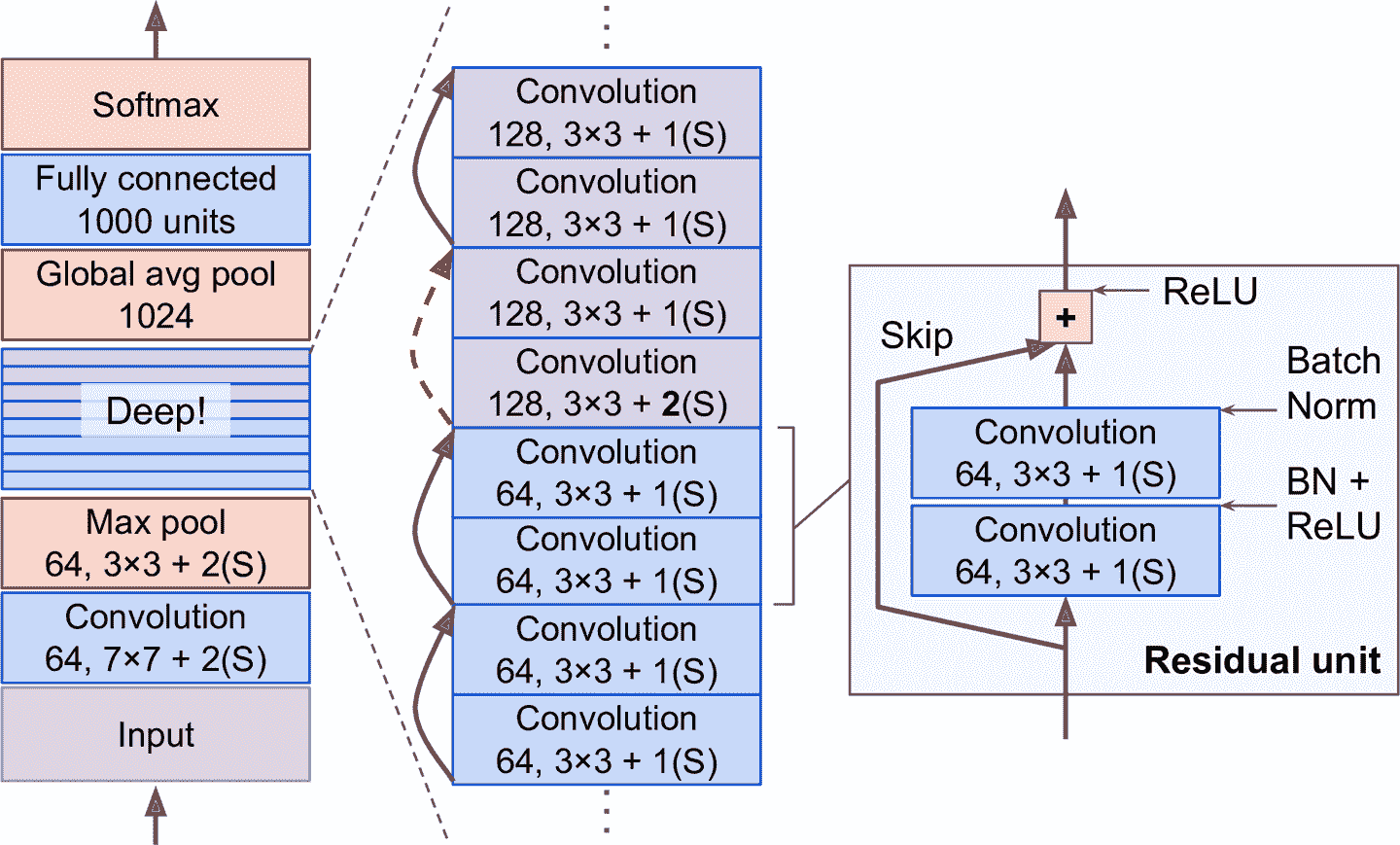
图 14-17 ResNet 架构
注意到,每经过几个残差单元,特征映射的数量就会翻倍,同时高度和宽度都减半()卷积层的步长为 2。发生这种情况时,因为形状不同(见图 14-17 中虚线的跳连接),输入不能直接添加到残差单元的输出上。要解决这个问题,输入要经过一个1 × 1的卷积层,步长为 2,特征映射数不变(见图 14-18)。
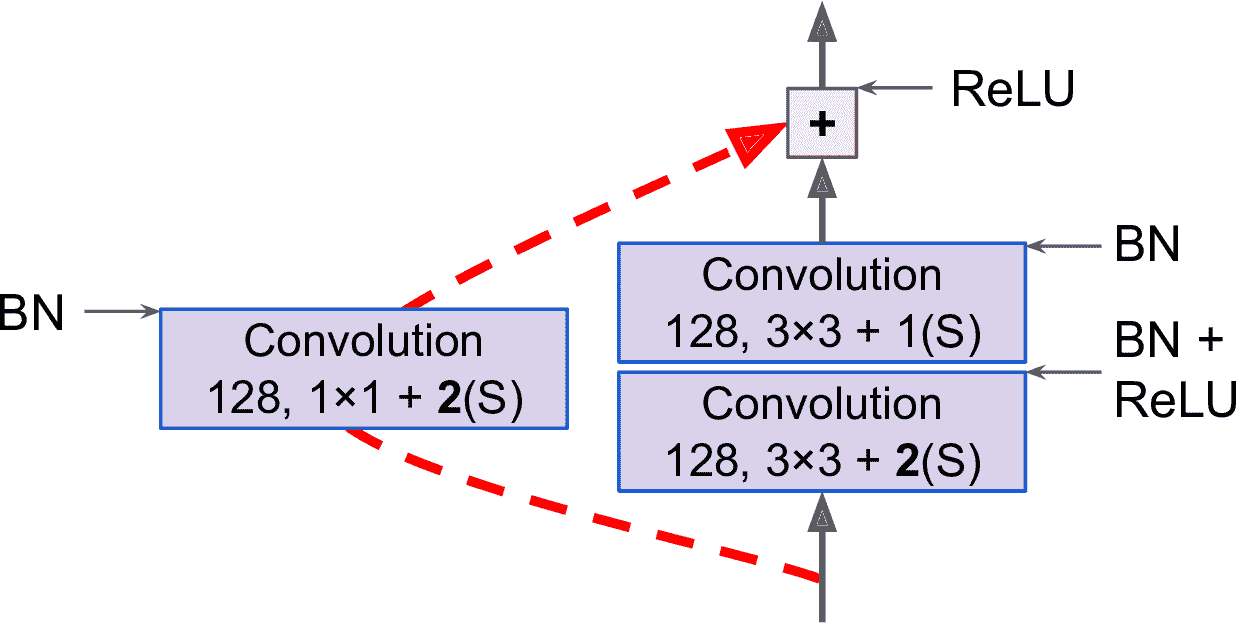
图 14-18 改变特征映射大小和深度时的跳连接
ResNet-34 是有 34 个层(只是计数了卷积层和全连接层)的 ResNet,有 3 个输出 64 个特征映射的残差单元,4 个输出 128 个特征映射的残差单元,6 个输出 256 个特征映射的残差单元,3 个输出 512 个特征映射的残差单元。本章后面会实现这个网络。
ResNet 通常比这个架构要深,比如 ResNet-152,使用了不同的残差单元。不是用3 × 3的输出 256 个特征映射的卷积层,而是用三个卷积层:第一是1 × 1的卷积层,只有 64 个特征映射(少 4 倍),作为瓶颈层使用;然后是1 × 1的卷积层,有 64 个特征映射;最后是另一个1 × 1的卷积层,有 256 个特征映射,恢复原始深度。ResNet-152 含有 3 个这样输出 256 个映射的残差单元,8 个输出 512 个映射的残差单元,36 个输出 1024 个映射的残差单元,最后是 3 个输出 2048 个映射的残差单元。
笔记:Google 的 Inception-v4 融合了 GoogLeNet 和 ResNet,使 ImageNet 的 top-5 误差率降低到接近 3%。
Xception
另一个 GoogLeNet 架构的变体是 Xception(Xception 的意思是极限创始,Extreme Inception)。它是由 François Chollet(Keras 的作者)在 2016 年提出的,Xception 在大型视觉任务(3.5 亿张图、1.7 万个类)上超越了 Inception-v3。和 Inception-v4 很像,Xception 融合了 GoogLeNet 和 ResNet,但将创始模块替换成了一个特殊类型的层,称为深度可分卷积层(或简称为可分卷积层)。深度可分卷积层在以前的 CNN 中出现过,但不像 Xception 这样处于核心。常规卷积层使用过滤器同时获取空间图案(比如,椭圆)和交叉通道图案(比如,嘴+鼻子+眼睛=脸),可分卷积层的假设是空间图案和交叉通道图案可以分别建模(见图 14-19)。因此,可分卷积层包括两部分:第一个部分对于每个输入特征映射使用单空间过滤器,第二个部分只针对交叉通道图案 —— 就是一个过滤器为1 × 1的常规卷积层。
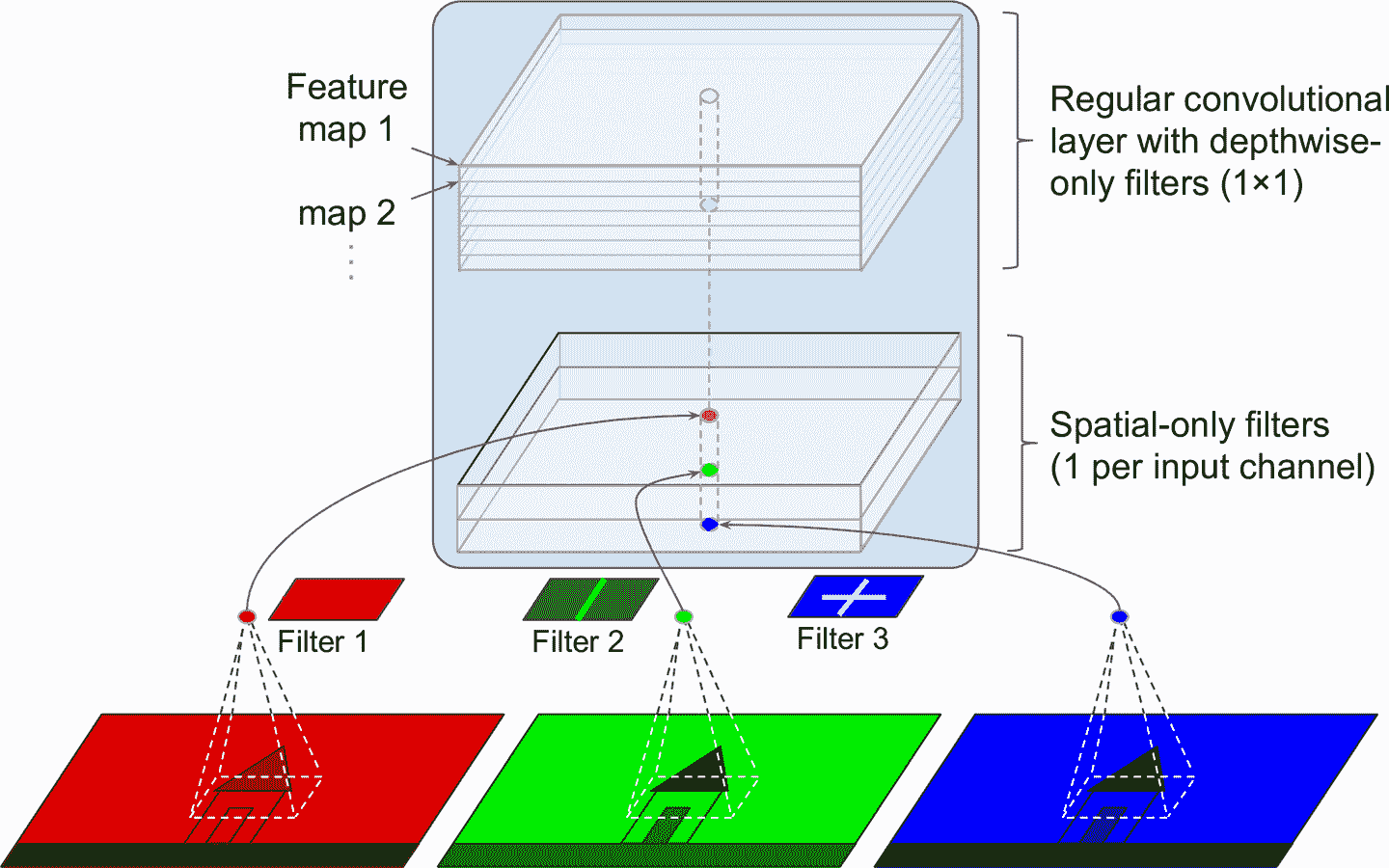
图 14-19 深度可分卷积层
因为可分卷积层对每个输入通道只有一个空间过滤器,要避免在通道不多的层之后使用可分卷积层,比如输入层(这就是图 14-19 要展示的)。出于这个原因,Xception 架构一开始有 2 个常规卷积层,但剩下的架构都使用可分卷积层(共 34 个),加上一些最大池化层和常规的末端层(全局平均池化层和紧密输出层)。
为什么 Xception 是 GoogLeNet 的变体呢,因为它并没有创始模块?正像前面讨论的,创始模块含有过滤器为1 × 1的卷积层:只针对交叉通道图案。但是,它们上面的常规卷积层既针对空间、也针对交叉通道图案。所以可以将创始模块作为常规卷积层和可分卷积层的中间状态。在实际中,可分卷积层表现更好。
提示:相比于常规卷积层,可分卷积层使用的参数、内存、算力更少,性能也更好,所以应默认使用后者(除了通道不多的层)。
ILSVRC 2016 的冠军是香港中文大学的 CUImage 团队。他们结合使用了多种不同的技术,包括复杂的对象识别系统,称为 GBD-Net,top-5 误差率达到 3% 以下。尽管结果很经验,但方案相对于 ResNet 过于复杂。另外,一年后,另一个简单得多的架构取得了更好的结果。
SENet
ILSVRC 2017 年的冠军是挤压-激活网络(Squeeze-and-Excitation Network (SENet))。这个架构拓展了之前的创始模块和 ResNet,提高了性能。SENet 的 top-5 误差率达到了惊人的 2.25%。经过拓展之后的版本分别称为 SE-创始模块和 SE-ResNet。性能提升来自于 SENet 在原始架构的每个单元(比如创始模块或残差单元)上添加了一个小的神经网络,称为 SE 块,见图 14-20。
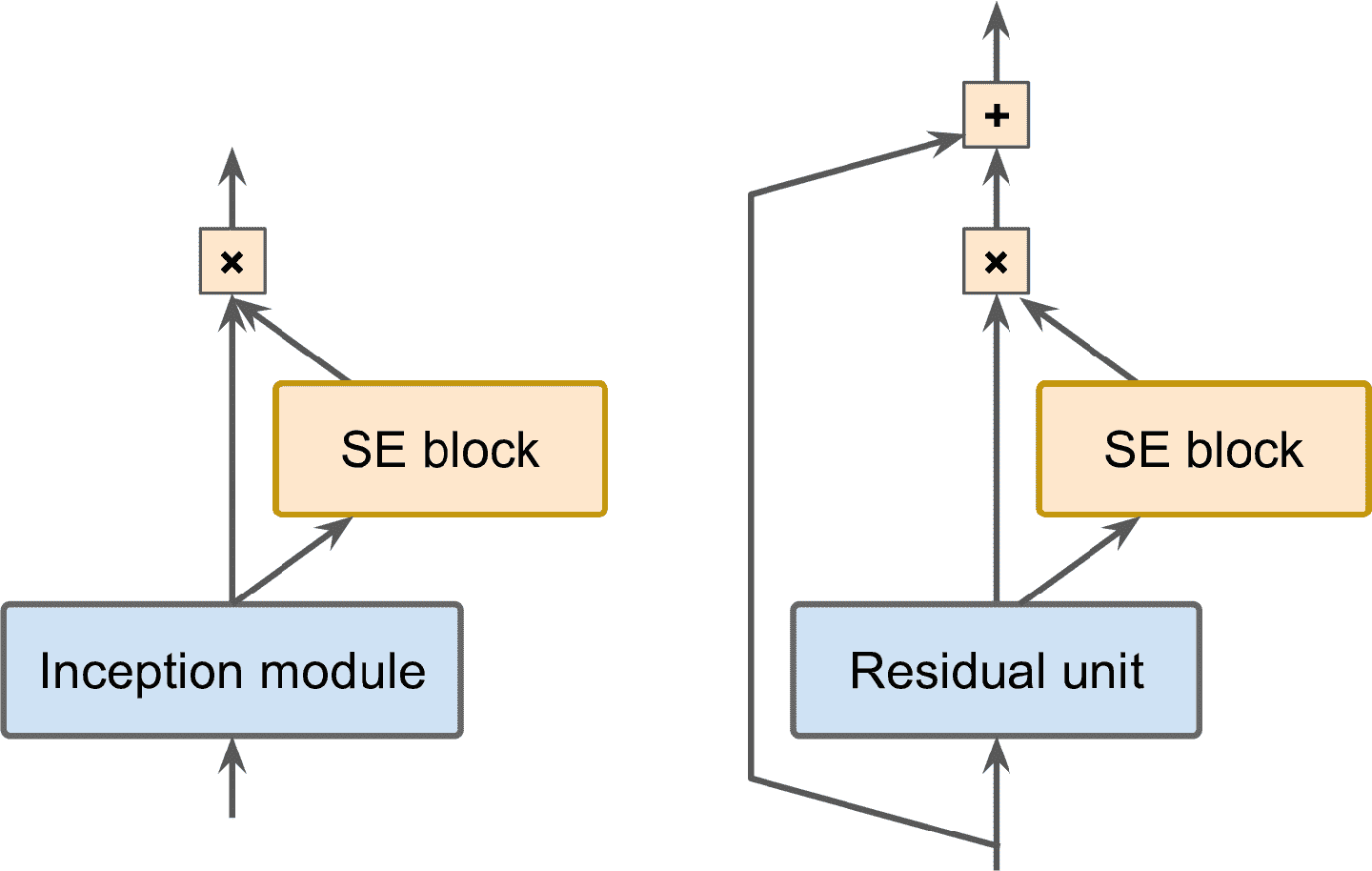
图 14-20 SE-创始模块(左)和 SE-ResNet(右)
SE 分析了单元输出,只针对深度方向,它能学习到哪些特征总是一起活跃的。然后根据这个信息,重新调整特征映射,见图 14-21。例如,SE 可以学习到嘴、鼻子、眼睛经常同时出现在图片中:如果你看见了罪和鼻子,通常是期待看见眼睛。所以,如果 SE 块发向嘴和鼻子的特征映射有强激活,但眼睛的特征映射没有强激活,就会提升眼睛的特征映射(更准确的,会降低无关的特征映射)。如果眼睛和其它东西搞混了,特征映射重调可以解决模糊性。
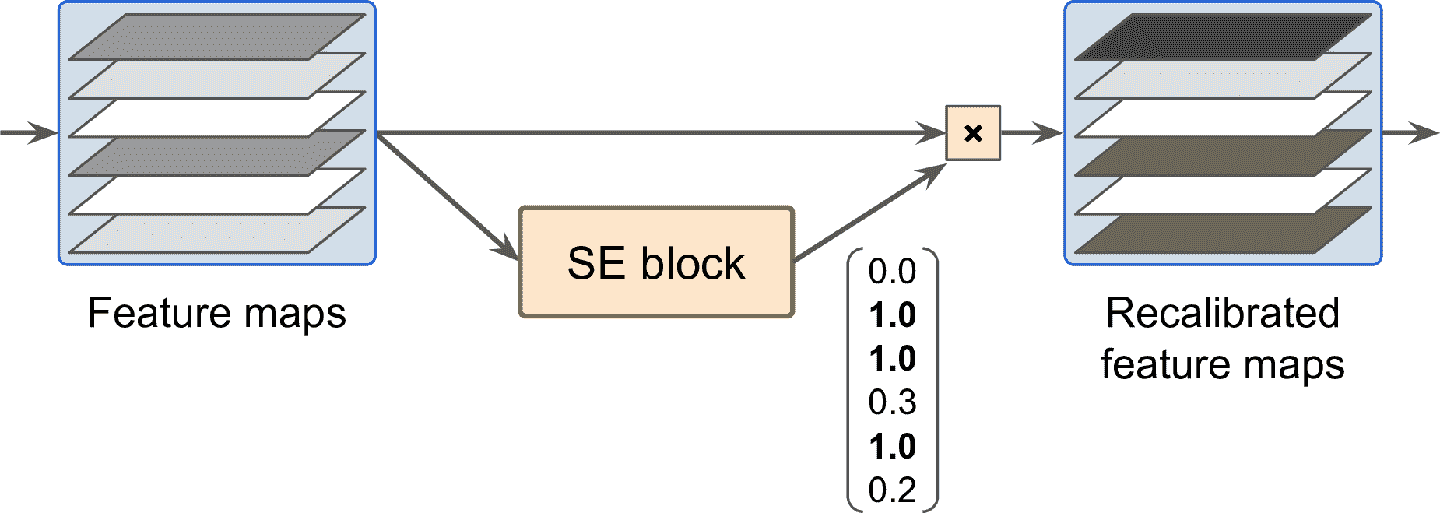
图 14-21 SE 快做特征重调
SE 块由三层组成:一个全局平均池化层、一个使用 ReLU 的隐含紧密层、一个使用 sigmoid 的紧密输出层(见图 14-22)。
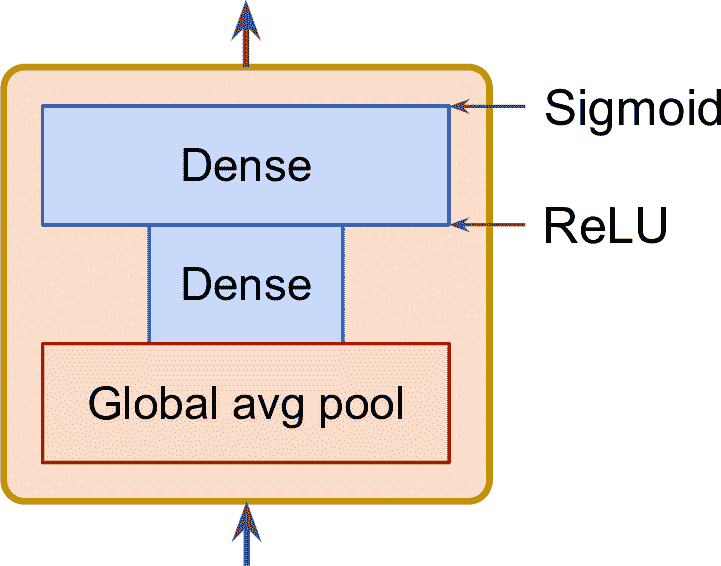
图 14-22 SE 块的结构
和之前一样,全局平均池化层计算每个特征映射的平均激活:例如,如果它的输入包括 256 个特征映射,就会输出 256 个数,表示对每个过滤器的整体响应水平。下一个层是“挤压”步骤:这个层的神经元数远小于 256,通常是小于特征映射数的 16 倍(比如 16 个神经元)—— 因此 256 个数被压缩金小向量中(16 维)。这是特征响应的地位向量表征(即,嵌入)。这一步作为瓶颈,能让 SE 块强行学习特征组合的通用表征(第 17 章会再次接触这个原理)。最后,输出层使用这个嵌入,输出一个重调向量,每个特征映射(比如,256)包含一个数,都位于 0 和 1 之间。然后,特征映射乘以这个重调向量,所以无关特征(其重调分数小)就被弱化了,就剩下相关特征(重调分数接近于 1)了。
用 Karas 实现 ResNet-34 CNN
目前为止介绍的大多数 CNN 架构的实现并不难(但经常需要加载预训练网络)。接下来用 Keras 实现 ResNet-34。首先,创建ResidualUnit层:
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
keras.layers.Conv2D(filters, 3, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
可以看到,这段代码和图 14-18 很接近。在构造器中,创建了所有需要的层:主要的层位于图中右侧,跳跃层位于左侧(只有当步长大于 1 时需要)。在call()方法中,我们让输入经过主层和跳跃层,然后将输出相加,再应用激活函数。
然后,使用Sequential模型搭建 ResNet-34,ResNet-34 就是一连串层的组合(将每个残差单元作为一个单一层):
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3],
padding="same", use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
这段代码中唯一麻烦的地方,就是添加ResidualUnit层的循环部分:前 3 个 RU 有 64 个过滤器,接下来的 4 个 RU 有 128 个过滤器,以此类推。如果过滤器数和前一 RU 层相同,则步长为 1,否则为 2。然后添加ResidualUnit,然后更新prev_filters。
不到 40 行代码就能搭建出 ILSVRC 2015 年冠军模型,既体现出 ResNet 的优美,也展现了 Keras API 的表达力。实现其他 CNN 架构也不困难。但是 Keras 内置了其中一些架构,一起尝试下。
使用 Keras 的预训练模型
通常来讲,不用手动实现 GoogLeNet 或 ResNet 这样的标准模型,因为keras.applications中已经包含这些预训练模型了,只需一行代码就成。例如,要加载在 ImageNet 上预训练的 ResNet-50 模型,使用下面的代码就行:
model = keras.applications.resnet50.ResNet50(weights="imagenet")
仅此而已!这样就能穿件一个 ResNet-50 模型,并下载在 ImageNet 上预训练的权重。要使用它,首先要保证图片有正确的大小。ResNet-50 模型要用224 × 224像素的图片(其它模型可能是299 × 299),所以使用 TensorFlow 的tf.image.resize()函数来缩放图片:
images_resized = tf.image.resize(images, [224, 224])
提示:
tf.image.resize()不会保留宽高比。如果需要,可以裁剪图片为合适的宽高比之后,再进行缩放。两步可以通过tf.image.crop_and_resize()来实现。
预训练模型的图片要经过特别的预处理。在某些情况下,要求输入是 0 到 1,有时是 -1 到 1,等等。每个模型提供了一个preprocess_input()函数,来对图片做预处理。这些函数假定像素值的范围是 0 到 255,因此需要乘以 255(因为之前将图片缩减到 0 和 1 之间):
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
现在就可以用预训练模型做预测了:
Y_proba = model.predict(inputs)
和通常一样,输出Y_proba是一个矩阵,每行是一张图片,每列是一个类(这个例子中有 1000 类)。如果想展示 top K 预测,要使用decode_predictions()函数,将每个预测出的类的名字和概率包括进来。对于每张图片,返回 top K 预测的数组,每个预测表示为包含类标识符、名字和置信度的数组:
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
输出如下:
Image #0
n03877845 - palace 42.87%
n02825657 - bell_cote 40.57%
n03781244 - monastery 14.56%
Image #1
n04522168 - vase 46.83%
n07930864 - cup 7.78%
n11939491 - daisy 4.87%
正确的类(monastery和daisy)出现在 top3 的结果中。考虑到,这是从 1000 个类中挑出来的,结果相当不错。
可以看到,使用预训练模型,可以非常容易的创建出一个效果相当不错的图片分类器。keras.applications中其它视觉模型还有几种 ResNet 的变体,GoogLeNet 的变体(比如 Inception-v3 和 Xception),VGGNet 的变体,MobileNet 和 MobileNetV2(移动设备使用的轻量模型)。
如果要使用的图片分类器不是给 ImageNet 图片做分类的呢?这时,还是可以使用预训练模型来做迁移学习。
使用预训练模型做迁移学习
如果想创建一个图片分类器,但没有足够的训练数据,使用预训练模型的低层通常是不错的主意,就像第 11 章讨论过的那样。例如,使用预训练的 Xception 模型训练一个分类花的图片的模型。首先,使用 TensorFlow Datasets 加载数据集(见 13 章):
import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
可以通过设定with_info=True来获取数据集信息。这里,获取到了数据集的大小和类名。但是,这里只有"train"训练集,没有测试集和验证集,所以需要分割训练集。TF Datasets 提供了一个 API 来做这项工作。比如,使用数据集的前 10% 作为测试集,接着的 15% 来做验证集,剩下的 75% 来做训练集:
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10, 15, 75])
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)
然后,必须要预处理图片。CNN 的要求是224 × 224的图片,所以需要缩放。还要使用 Xception 的preprocess_input()函数来预处理图片:
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
对三个数据集使用这个预处理函数,打散训练集,给所有的数据集添加批次和预提取:
batch_size = 32
train_set = train_set.shuffle(1000)
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)
如果想做数据增强,可以修改训练集的预处理函数,给训练图片添加一些转换。例如,使用tf.image.random_crop()随机裁剪图片,使用tf.image.random_flip_left_right()做随机水平翻转,等等(参考笔记本的“使用预训练模型做迁移学习”部分)。
提示:
keras.preprocessing.image.ImageDataGenerator可以方便地从硬盘加载图片,并用多种方式来增强:偏移、旋转、缩放、翻转、裁剪,或使用任何你想做的转换。对于简单项目,这么做很方便。但是,使用tf.data管道的好处更多:从任何数据源高效读取图片(例如,并行);操作数据集;如果基于tf.image运算编写预处理函数,既可以用在tf.data管道中,也可以用在生产部署的模型中(见第 19 章)。
然后加载一个在 ImageNet 上预训练的 Xception 模型。通过设定include_top=False,排除模型的顶层:排除了全局平均池化层和紧密输出层。我们然后根据基本模型的输出,添加自己的全局平均池化层,然后添加紧密输出层(没有一个类就有一个单元,使用 softmax 激活函数)。最后,创建 Keras 模型:
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.Model(inputs=base_model.input, outputs=output)
第 11 章介绍过,最好冻结预训练层的权重,至少在训练初期如此:
for layer in base_model.layers:
layer.trainable = False
笔记:因为我们的模型直接使用了基本模型的层,而不是
base_model对象,设置base_model.trainable=False没有任何效果。
最后,编译模型,开始训练:
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(train_set, epochs=5, validation_data=valid_set)
警告:训练过程非常慢,除非使用 GPU。如果没有 GPU,应该在 Colab 中运行本章的笔记本,使用 GPU 运行时(是免费的!)。见这里。
模型训练几个周期之后,它的验证准确率应该可以达到 75-80%,然后就没什么提升了。这意味着上层训练的差不多了,此时可以解冻所有层(或只是解冻上边的层),然后继续训练(别忘在冷冻和解冻层是编译模型)。此时使用小得多的学习率,以避免破坏预训练的权重:
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(...)
history = model.fit(...)
训练要花不少时间,最终在测试集上的准确率可以达到 95%。有个模型,就可以训练出惊艳的图片分类器了!计算机视觉除了分类,还有其它任务,比如,想知道花在图片中的位置,该怎么做呢?
分类和定位
第 10 章讨论过,定位图片中的物体可以表达为一个回归任务:预测物体的范围框,一个常见的方法是预测物体中心的水平和垂直坐标,和其高度和宽度。不需要大改模型,只要再添加一个有四个单元的紧密输出层(通常是在全局平均池化层的上面),可以用 MSE 损失训练:
base_model = keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # depends on what you care most about
optimizer=optimizer, metrics=["accuracy"])
但现在有一个问题:花数据集中没有围绕花的边框。因此,我们需要自己加上。这通常是机器学习任务中最难的部分:获取标签。一个好主意是花点时间来找合适的工具。给图片加边框,可供使用的开源图片打标签工具包括 VGG Image Annotator,、LabelImg,、OpenLabeler 或 ImgLab,或是商业工具,比如 LabelBox 或 Supervisely。还可以考虑众包平台,比如如果有很多图片要标注的话,可以使用 Amazon Mechanical Turk。但是,建立众包平台、准备数据格式、监督、保证质量,要做不少工作。如果只有几千张图片要打标签,又不是频繁来做,最好选择自己来做。Adriana Kovashka 等人写了一篇实用的计算机视觉方面的关于众包的论文,建议读一读。
假设你已经给每张图片的花都获得了边框。你需要创建一个数据集,它的项是预处理好的图片的批次,加上类标签和边框。每项应该是一个元组,格式是(images, (class_labels, bounding_boxes))。然后就可以准备训练模型了!
提示:边框应该做归一化,让中心的横坐标、纵坐标、宽度和高度的范围变成 0 到 1 之间。另外,最好是预测高和宽的平方根,而不是直接预测高和宽:大边框的 10 像素的误差,相比于小边框的 10 像素的误差,不会惩罚那么大。
MSE 作为损失函数来训练模型效果很好,但不是评估模型预测边框的好指标。最常见的指标是交并比(Intersection over Union (IoU)):预测边框与目标边框的重叠部分,除以两者的并集(见图 14-23)。在tf.keras中,交并比是用tf.keras.metrics.MeanIoU类来实现的。

图 14-23 交并比指标
完成了分类并定位单一物体,但如果图片中有多个物体该怎么办呢(常见于花数据集)?
目标检测
分类并定位图片中的多个物体的任务被称为目标检测。几年之前,使用的方法还是用定位单一目标的 CNN,然后将其在图片上滑动,见图 14-24。在这个例子中,图片被分成了6 × 8的网格,CNN(粗黑实线矩形)的范围是3 × 3。 当 CNN 查看图片的左上部分时,检测到了最左边的玫瑰花,向右滑动一格,检测到的还是同样的花。又滑动一格,检测到了最上的花,再向右一格,检测到的还是最上面的花。你可以继续滑动 CNN,查看所有6 × 8的区域。另外,因为目标的大小不同,还需要用不同大小的 CNN 来观察。例如,检测完了所有6 × 8的区域,可以继续用6 × 8的区域来检测。
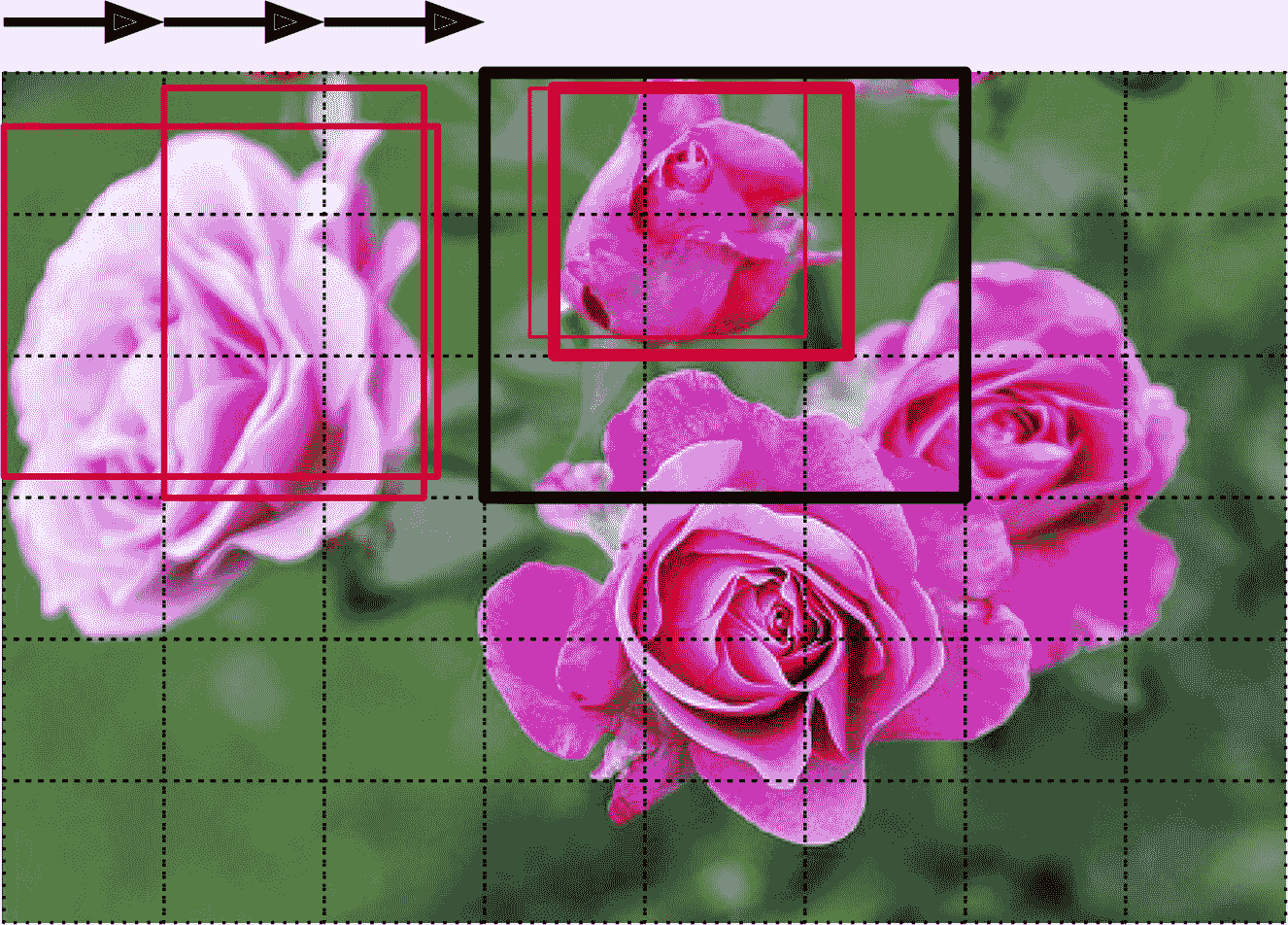
图 14-24 通过滑动 CNN 来检测多个目标
这个方法非常简单易懂,但是也看到了,它会在不同位置、多次检测到同样的目标。需要后处理,去除没用的边框,常见的方法是非极大值抑制(non-max suppression)。步骤如下:
-
首先,给 CNN 添加另一个对象性输出,来估计花确实出现在图片中的概率(或者,可以添加一个“没有花”的类,但通常不好使)。必须要使用 sigmoid 激活函数,可以用二元交叉熵损失函数来训练。然后删掉对象性分数低于某阈值的所有边框:这样能删掉所有不包含花的边框。
-
找到对象性分数最高的边框,然后删掉所有其它与之大面积重叠的边框(例如,IoU 大于 60%)。例如,在图 14-24 中,最大对象性分数的边框出现在最上面花的粗宾匡(对象性分数用边框的粗细来表示)。另一个边框和这个边框重合很多,所以将其删除。
-
重复这两个步骤,直到没有可以删除的边框。
用这个简单的方法来做目标检测的效果相当不错,但需要运行 CNN 好几次,所以很慢。幸好,有一个更快的方法来滑动 CNN:使用全卷积网络(fully convolutional network,FCN)。
全卷积层
FCN 是 Jonathan Long 在 2015 年的一篇论文汇总提出的,用于语义分割(根据所属目标,对图片中的每个像素点进行分类)。作者指出,可以用卷积层替换 CNN 顶部的紧密层。要搞明白,看一个例子:假设一个 200 个神经元的紧密层,位于卷积层的上边,卷积层输出 100 个特征映射,每个大小是7 × 7(这是特征映射的大小,不是核大小)。每个神经元会计算卷积层的100 × 7 × 7个激活结果的加权和(加上偏置项)。现在将紧密层替换为卷积层,有 200 个过滤器,每个大小为7 × 7,"valid"填充。这个层能输出 200 个特征映射,每个是7 × 7(因为核大小等于输入特征映射的大小,并且使用的是"valid"填充)。换句话说,会产生 200 个数,和紧密层一样;如果仔细观察卷积层的计算,会发现这些书和紧密层输出的数一模一样。唯一不同的地方,紧密层的输出的张量形状是[批次大小, 200],而卷积层的输出的张量形状是[批次大小, 1, 1, 200]。
提示:要将紧密层变成卷积层,卷积层中的过滤器的数量,必须等于紧密层的神经元数,过滤器大小必须等于输入特征映射的大小,必须使用
"valid"填充。步长可以是 1 或以上。
为什么这点这么重要?紧密层需要的是一个具体的输入大小(因为它的每个输入特征都有一个权重),卷积层却可以处理任意大小的图片(但是,它也希望输入有一个确定的通道数,因为每个核对每个输入通道包含一套不同的权重集合)。因为 FCN 只包含卷积层(和池化层,属性相同),所以可以在任何大小的图片上训练和运行。
举个例子,假设已经训练好了一个用于分类和定位的 CNN。图片大小是224 × 224,输出 10 个数:输出 0 到 4 经过 softmax 激活函数,给出类的概率;输出 5 经过逻辑激活函数,给出对象性分数;输出 6 到 9 不经过任何激活函数,表示边框的中心坐标、高和宽。
现在可以将紧密层转换为卷积层。事实上,不需要再次训练,只需将紧密层的权重复制到卷积层中。另外,可以在训练前,将 CNN 转换成 FCN。
当输入图片为224 × 224时(见图 14-25 的左边),假设输出层前面的最后一个卷积层(也被称为瓶颈层)输出224 × 224的特征映射。如果 FCN 的输入图片是448 × 448(见图 14-25 的右边),瓶颈层会输出224 × 224的特征映射。因为紧密输出层被替换成了 10 个使用大小为224 × 224的过滤器的卷积层,"valid"填充,步长为 1,输出会有 10 个特征映射,每个大小为448 × 448(因为14 – 7 + 1 = 8)。换句话说,FCN 只会处理整张图片一次,会输出224 × 224的网格,每个格子有 10 个数(5 个类概率,1 个对象性分数,4 个边框参数)。就像之前滑动 CNN 那样,每行滑动 8 步,每列滑动 8 步。再形象的讲一下,将原始图片切分成224 × 224的网格,然后用224 × 224的窗口在上面滑动,窗口会有8 × 8 = 64个可能的位置,也就是 64 个预测。但是,FCN 方法又非常高效,因为只需观察图片一次。事实上,“只看一次”(You Only Look Once,YOLO)是一个非常流行的目标检测架构的名字,下面介绍。
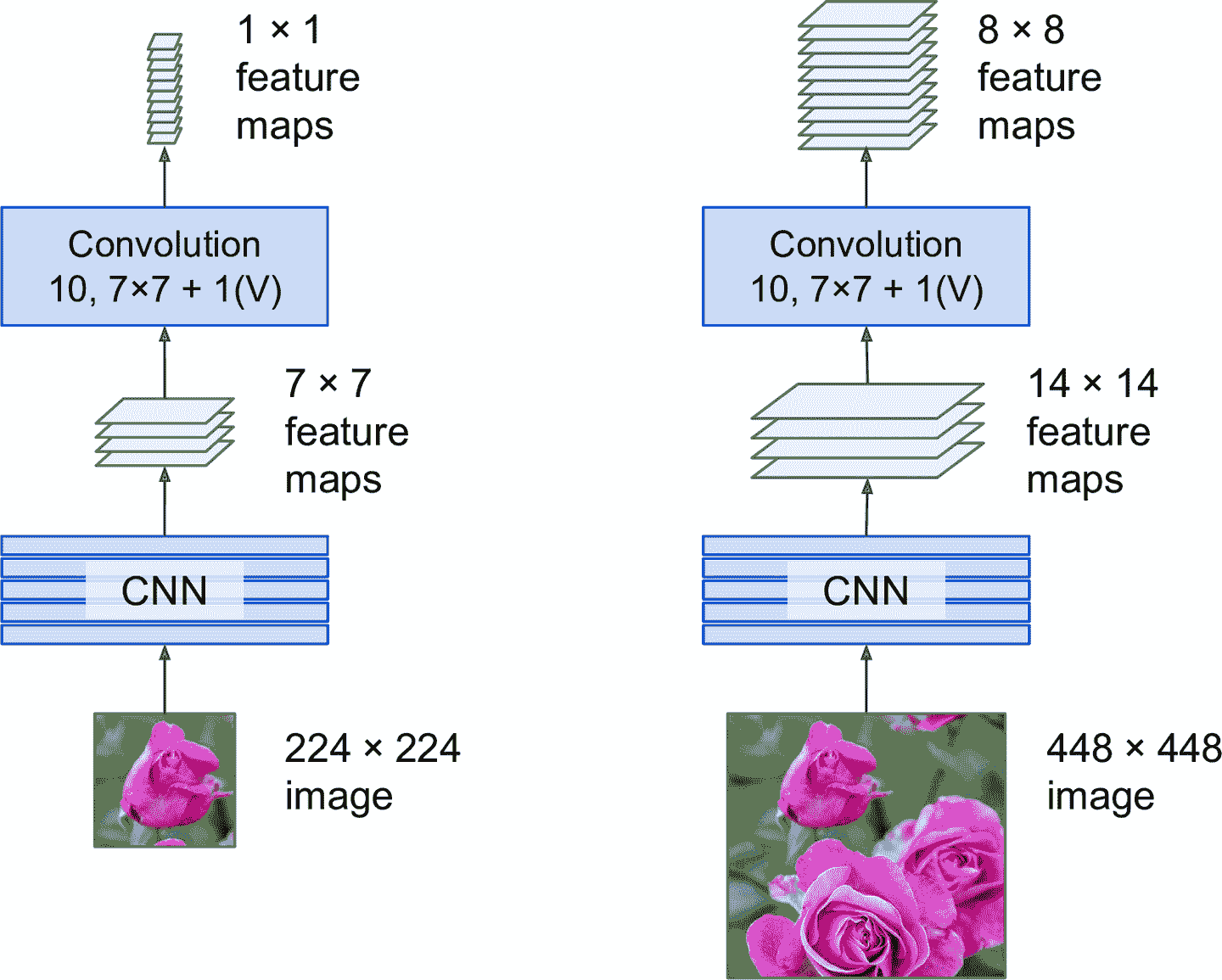
图 14-25 相同的 FCN 处理小图片(左)和大图片(右)
只看一次(YOLO)
YOLO 是一个非常快且准确的目标检测框架,是 Joseph Redmon 在 2015 年的一篇论文中提出的,2016 年优化为 YOLOv2,2018 年优化为 YOLOv3。速度快到甚至可以在实时视频中运行,可以看 Redmon 的这个例子(要翻墙)。
YOLOv3 的架构和之前讨论过的很像,只有一些重要的不同点:
-
每个网格输出 5 个边框(不是 1 个),每个边框都有一个对象性得分。每个网格还输出 20 个类概率,是在 PASCAL VOC 数据集上训练的,这个数据集有 20 个类。每个网格一共有 45 个数:5 个边框,每个 4 个坐标参数,加上 5 个对象性分数,加上 20 个类概率。
-
YOLOv3 不是预测边框的绝对坐标,而是预测相对于网格坐标的偏置量,
(0, 0)是网格的左上角,(1, 1)是网格的右下角。对于每个网格,YOLOv3 是被训练为只能预测中心位于网格的边框(边框通常比网格大得多)。YOLOv3 对边框坐标使用逻辑激活函数,以保证其在 0 到 1 之间。 -
开始训练神经网络之前,YOLOv3 找了 5 个代表性边框维度,称为锚定框(anchor box)(或称为前边框)。它们是通过 K-Means 算法(见第 9 章)对训练集边框的高和宽计算得到的。例如,如果训练图片包含许多行人,一个锚定框就会获取行人的基本维度。然后当神经网络对每个网格预测 5 个边框时,实际是预测如何缩放每个锚定框。比如,假设一个锚定框是 100 个像素高,50 个像素宽,神经网络可能的预测是垂直放大到 1.5 倍,水平缩小为 0.9 倍。结果是
150 × 45的边框。更准确的,对于每个网格和每个锚定框,神经网络预测其垂直和水平缩放参数的对数。有了锚定框,可以更容易预测出边框,因为可以更快的学到边框的样子,速度也会更快。 -
神经网络是用不同规模的图片来训练的:每隔几个批次,网络就随机调训新照片维度(从
330 × 330到330 × 330像素)。这可以让网络学到不同的规模。另外,还可以在不同规模上使用 YOLOv3:小图比大图快但准确性差。
还可能有些有意思的创新,比如使用跳连接来恢复一些在 CNN 中损失的空间分辨率,后面讨论语义分割时会讨论。在 2016 年的这篇论文中,作者介绍了使用层级分类的 YOLO9000 模型:模型预测视觉层级(称为词树,WordTree)中的每个节点的概率。这可以让网络用高置信度预测图片表示的是什么,比如狗,即便不知道狗的品种。建议阅读这三篇论文:不仅文笔不错,还给出不少精彩的例子,介绍深度学习系统是如何一点一滴进步的。
平均精度均值(mean Average Precision,mAP)
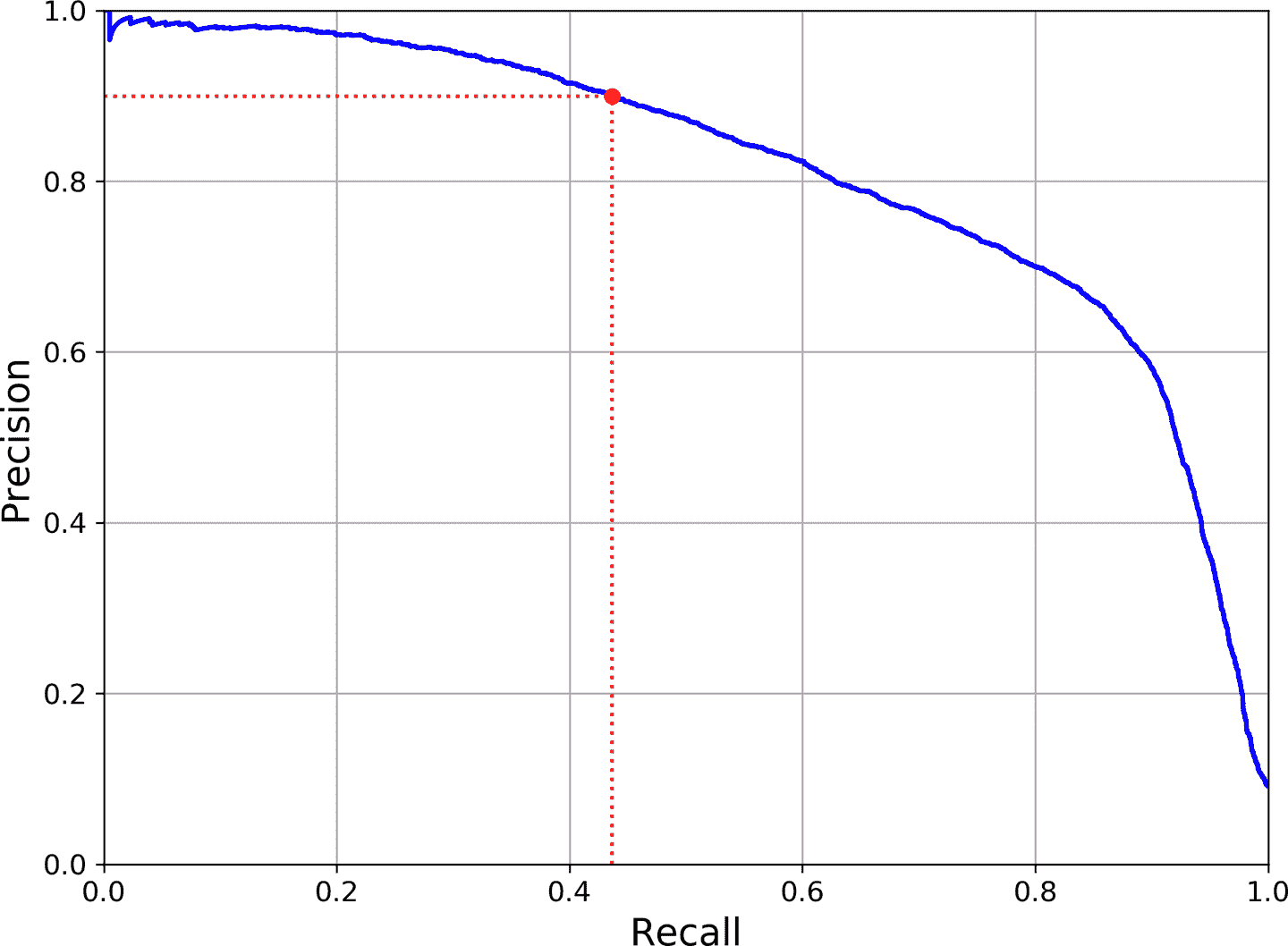
目标检测中非常常见的指标是平均精度均值。“平均均值”听起来啰嗦了。要弄明白这个指标,返回到第 3 章中的两个分类指标:精确率和召回率。取舍关系:召回率越高,精确率就越低。可以在精确率/召回率曲线上看到。将这条曲线归纳为一个数,可以计算曲线下面积(AUC)。但精确率/召回率曲线上有些部分,当精确率上升时,召回率也上升,特别是当召回率较低时(可以在图 3-5 的顶部看到)。这就是产生 mAP 的激励之一。
图 3-5 精确率 vs 召回率
假设当召回率为 10% 时,分类器的精确率是 90%,召回率为 20% 时,精确率是 96%。这里就没有取舍关系:使用召回率为 20% 的分类器就好,因为此时精确率更高。所以当召回率至少有 10% 时,需要找到最高精确率,即 96%。因此,一个衡量模型性能的方法是计算召回率至少为 0% 时,计算最大精确率,再计算召回率至少为 10% 时的最大精确率,再计算召回率至少为 20% 时的最大精确率,以此类推。最后计算这些最大精确率的平均值,这个指标称为平均精确率(Average Precision,AP)。当有超过两个类时,可以计算每个类的 AP,然后计算平均 AP(即,mAP)。就是这样!
在目标检测中,还有另外一个复杂度:如果系统检测到了正确的类,但是定位错了(即,边框不对)?当然不能将其作为正预测。一种方法是定义 IOU 阈值:例如,只有当 IOU 超过 0.5 时,预测才是正确的。相应的 mAP 表示为 mAP@0.5(或 mAP@50%,或 AP50)。在一些比赛中(比如 PASCAL VOC 竞赛),就是这么做的。在其它比赛中(比如,COCO),mAP 是用不同 IOU 阈值(0.50, 0.55, 0.60, …, 0.95)计算的。最终指标是所有这些 mAP 的均值(表示为 AP@[.50:.95] 或 AP@[.50:0.05:.95]),这是均值的均值。
一些 YOLO 的 TensorFlow 实现可以在 GitHub 上找到。可以看看 Zihao Zang 用 TensorFlow 2 实现的项目。TensorFlow Models 项目中还有其它目标检测模型;一些还传到了 TF Hub,比如 SSD 和 Faster-RCNN,这两个都很流行。SSD 也是一个“一次”检测模型,类似于 YOLO。Faster R-CNN 复杂一些:图片先经过 CNN,然后输出经过区域提议网络(Region Proposal Network,RPN),RPN 对边框做处理,更容易圈住目标。根据 CNN 的裁剪输出,每个边框都运行这一个分类器。
检测系统的选择取决于许多因素:速度、准确率、预训练模型是否可用、训练时间、复杂度,等等。论文中有许多指标表格,但测试环境的变数很多。技术进步也很快,很难比较出哪个更适合大多数人,并且有效期可以长过几个月。
语义分割
在语义分割中,每个像素根据其所属的目标来进行分类(例如,路、汽车、行人、建筑物,等等),见图 14-26。注意,相同类的不同目标是不做区分的。例如,分割图片的右侧的所有自行车被归类为一坨像素。这个任务的难点是当图片经过常规 CNN 时,会逐渐丢失空间分辨率(因为有的层的步长大于 1);因此,常规的 CNN 可以检测出图片的左下有一个人,但不知道准确的位置。
和目标检测一样,有多种方法来解决这个问题,其中一些比较复杂。但是,之前说过,Jonathan Long 等人在 2015 年的一篇论文中提出乐意简单的方法。作者先将预训练的 CNN 转变为 FCN,CNN 使用 32 的总步长(即,将所有大于 1 的步长相加)作用到输入图片上,最后一层的输出特征映射比输入图片小 32 倍。这样过于粗糙,所以添加了一个单独的上采样层,将分辨率乘以 32。

图 14-26 语义分割
有几种上采样(增加图片大小)的方法,比如双线性插值,但只在×4或×8时好用。Jonathan Long 等人使用了转置卷积层:等价于,先在图片中插入空白的行和列(都是 0),然后做一次常规卷积(见图 14-27)。或者,有人将其考虑为常规卷积层,使用分数步长(比如,图 14-27 中是1/2)。转置卷积层一开始的表现和线性插值很像,但因为是可训练的,在训练中会变得更好。在tf.keras中,可以使用Conv2DTranspose层。
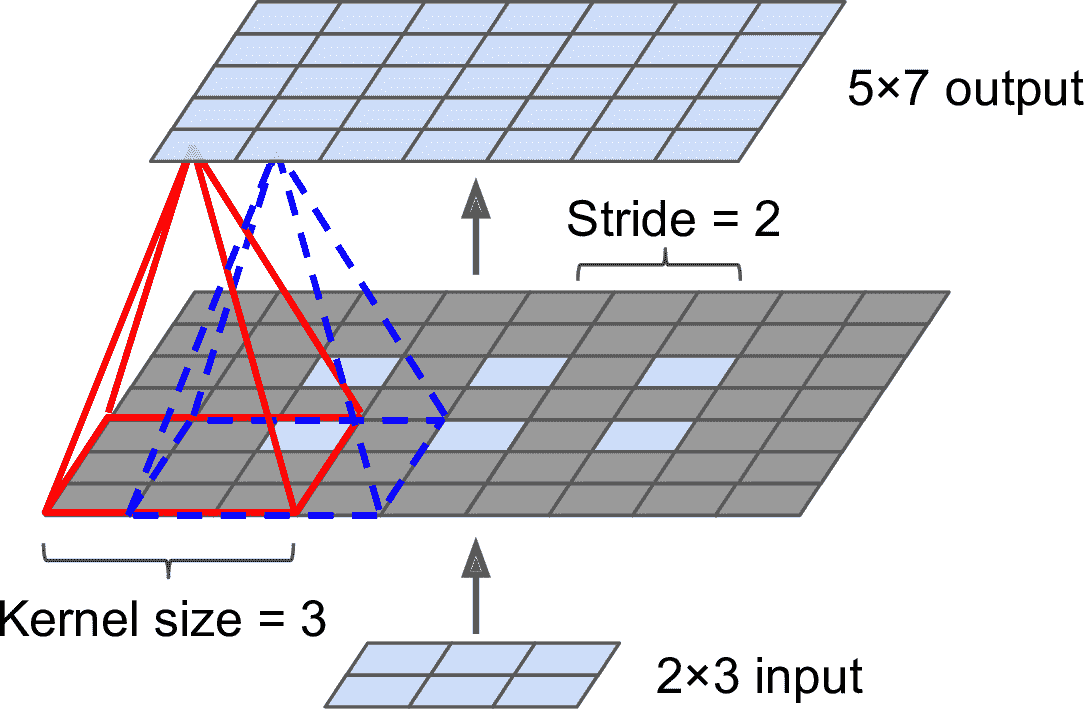
图 14-27 使用转置卷积层做上采样
笔记:在转置卷积层中,步长定义为输入图片被拉伸的倍数,而不是过滤器步长。所以步长越大,输出也就越大(和卷积层或池化层不同)。
TensorFlow 卷积运算
TensorFlow 还提供了一些其它类型的卷积层:
keras.layers.Conv1D:为 1D 输入创建卷积层,比如时间序列或文本,第 15 章会见到。
keras.layers.Conv3D:为 3D 输入创建卷积层,比如 3D PET 扫描。
dilation_rate:将任何卷积层的dilation_rate超参数设为 2 或更大,可以创建有孔卷积层。等价于常规卷积层,加上一个膨胀的、插入了空白行和列的过滤器。例如,一个1 × 3的过滤器[[1,2,3]],膨胀 4 倍,就变成了[[1, 0, 0, 0, 2, 0, 0, 0, 3]]。这可以让卷积层有一个更大的感受野,却没有增加计算量和额外的参数。
tf.nn.depthwise_conv2d():可以用来创建深度方向卷积层(但需要自己创建参数)。它将每个过滤器应用到每个独立的输入通道上。因此,因此,如果有f[n]个过滤器和f[n']个输入通道,就会输出f[n] x f[n']个特征映射。
这个方法行得通,但还是不够准确。要做的更好,作者从低层开始就添加了跳连接:例如,他们使用因子 2(而不是 32)对输出图片做上采样,然后添加一个低层的输出。然后对结果做因子为 16 的上采样,总的上采样因子为 32(见图 14-28)。这样可以恢复一些在早期池化中丢失的空间分辨率。在他们的最优架构中,他们使用了两个相似的跳连接,以从更低层恢复更小的细节。
总之,原始 CNN 的输出又经过了下面的步骤:上采样×2,加上一个低层的输出(形状相同),上采样×2,加上一个更低层的输出,最后上采样×8。甚至可以放大,超过原图大小:这个方法可以用来提高图片的分辨率,这个技术成为超-分辨率。
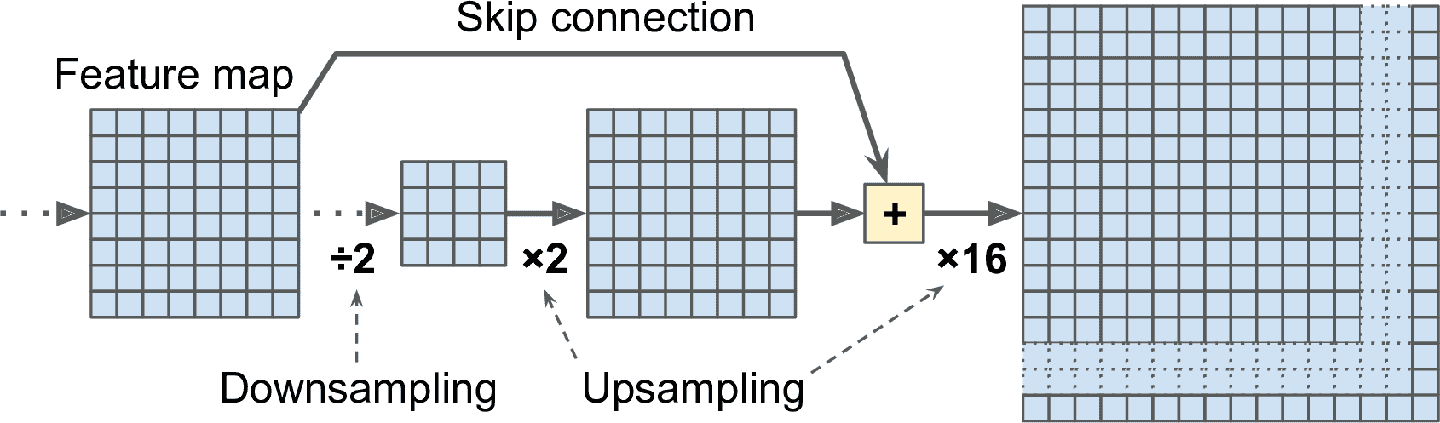
图 14-28 跳连接可以从低层恢复一些空间分辨率
许多 GitHub 仓库提供了语义分割的 TensorFlow 实现,还可以在 TensorFlow Models 中找到预训练的实例分割模型。实例分割和语义分割类似,但不是将相同类的所有物体合并成一坨,而是将每个目标都分开(可以将每辆自行车都分开)。目前,TensorFlow Models 中可用的实例分割时基于 Mask R-CNN 架构的,是在 2017 年的一篇论文中提出的:通过给每个边框做一个像素罩,拓展 Faster R-CNN 模型。所以不仅能得到边框,还能获得边框中像素的像素罩。
可以发现,深度计算机视觉领域既宽广又发展迅速,每年都会产生新的架构,都是基于卷积神经网络的。最近几年进步惊人,研究者们现在正聚焦于越来越难的问题,比如对抗学习(可以让网络对具有欺骗性的图片更有抵抗力),可解释性(理解为什么网络做出这样的分类),实时图像生成(见第 17 章),一次学习(观察一次,就能认出目标呃系统)。一些人在探索全新的架构,比如 Geoffrey Hinton 的胶囊网络(见视频,笔记本中有对应的代码)。下一章会介绍如何用循环神经网络和卷积神经网络来处理序列数据,比如时间序列。
练习
-
对于图片分类,CNN 相对于全连接 DNN 的优势是什么?
-
考虑一个 CNN,有 3 个卷积层,每个都是
3 × 3的核,步长为 2,零填充。最低的层输出 100 个特征映射,中间的输出 200 个特征映射,最上面的输出 400 个。输入图片是3 × 3像素的 RGB 图。这个 CNN 的总参数量是多少?如果使用 32 位浮点数,做与测试需要多少内存?批次是 50 张图片,训练时的内存消耗是多少? -
如果训练 CNN 时 GPU 内存不够,解决该问题的 5 种方法是什么?
-
为什么使用最大池化层,而不是同样步长的卷积层?
-
为什么使用局部响应归一化层?
-
AlexNet 想对于 LeNet-5 的创新在哪里?GoogLeNet、ResNet、SENet、Xception 的创新又是什么?
-
什么是全卷积网络?如何将紧密层转变为卷积层?
-
语义分割的主要技术难点是什么?
-
从零搭建你的 CNN,并在 MNIST 上达到尽可能高的准确率。
-
使用迁移学习来做大图片分类,经过下面步骤:
a. 创建每个类至少有 100 张图片的训练集。例如,你可以用自己的图片基于地点来分类(沙滩、山、城市,等等),或者使用现成的数据集(比如从 TensorFlow Datasets)。
b. 将其分成训练集、验证集、训练集。
c. 搭建输入管道,包括必要的预处理操作,最好加上数据增强。
d. 在这个数据集上,微调预训练模型。
- 尝试下 TensorFlow 的风格迁移教程。用深度学习生成艺术作品很有趣。
